16. Gamma 模型¶
指数分布是预测 下一次 时间发生等待的时间, 更进一步,如果需要预测第k次事件发生需要等待的时间呢? 这就是 Gamma 分布。 在介绍 Gamma 分布之前,先简单的介绍一下 Gamma 函数。
16.1. Gamma 函数¶
https://www.probabilitycourse.com/chapter4/4_2_4_Gamma_distribution.php
16.2. Gamma 分布¶
在之前的章节我们已经讨论了如何从泊松过程推导出指数分布, Gamma 分布的推导的过程是类似的。 不同的地方在于指数分布是等待下一次事件发生, 而 Gamma 分布是等待第k次事件的发生。
我们用符号 \(k\) 表示事件发生的次数, 符号 \(T\) 表示直到 \(k\) 次事件发生等待的时间,也就是目标随机变量。 \(\lambda\) 表示泊松过程中事件发生的频率(单位时间内发生的次数)。 \(p(T>t;k)\) 表示直到第 \(k\) 次事件发生等待的时间 \(T\) 大于 \(t\) 的概率。 用符号 \(p(k;T=t)\) 表示在泊松过程中 \(t\) 个时间单元内事件发生 \(k\) 次的概率。
泊松分布表示单位时间窗口内事件发生次数的概率分布, 泊松分布的概率分布函数为:
其表示在一个单位时间内事件发生 \(k\) 次的概率,唯一的参数 \(\lambda\) 表示单位时间内事件发生次数的平均值, 也就是 \(k\) 的期望值,\(\mathbb{E}[x]=\lambda\) 。 现在要想计算 \(t\) 个单位时间内事件发生的次数,只需要用 \(\lambda t\) 替换上式中的 \(\lambda\) 即可, \(t\) 个时间单元内事件发生 \(k\) 次的概率为:
备注
为什么用 \(\lambda t\) 替换 \(\lambda\) 就可以?
泊松分布表示单位时间内,随机事件发生 \(k\) 次的概率分布。 这个单位时间并没有具体的长度限制,只要保证每个时间片段的长度相同就可以。 泊松分布唯一的参数就是每个时间片段内随机事件发生次数的平均值 \(\lambda\) , 如果要算 \(t\) 个时间片段内随机事件发生次数的概率分布,相当于原来的时间片段扩大了 \(t\) 倍, 这个 \(t\) 倍的时间片段也可以看做是一个”单位时间”,这个新的”单位时间”组成一个新的泊松分布, 并且其平均值参数 \(\lambda_{new}\) 也是原来的 \(t\) 倍,即 \(\lambda_{new} = \lambda t\)。
泊松分布表示的是 一个单位时间片段内 随机事件发生 次数 的概率分布, 指数分布表示的是随机事件 第一次 发生的需要的 时间 的概率分布。 泊松分布描述的是 次数,是离散变量的分布; 指数分布描述的是 时间 ,是连续值变量的分布。 然而指数分布仅仅描述了事件首次发生,不能表示更多次事件发生,不具备一般化, Gamma 分布就是指数分布的扩展,能够表达事件发生任意次数所需 时间 的概率分布。
我们令符号 \(p(T>t;k)\) 表示随机事件发生 \(k\) 所需时间大于 \(t\) 的概率。 如果随机事件第 \(k\) 发生的时间大于 \(t\) , 意味着在 \(t\) 个时间单元内,事件发生次数一定是小于等于 \(k-1\) 次。 换句话说,\(t\) 个时间单元内最多只发生 \(k-1\) 次, 第 \(k\) 次发生的时间一定是大于 \(t\) 。 因此 \(p(T>t;k)\) 可以看成是在 \(t\) 个时间单元内,事件发生 \(0,1,2,...,k-1\) 次的概率之和。
现在我们得到了第 \(k\) 次事件发生时间大于 \(t\) 的概率 \(p(T>t;k)\) ,反过来,第 \(k\) 次事件发生时间小于等于 \(t\) 的概率为:
显然 公式(16.2.5) 是一个累积分布函数(Cumulative Distribution Function), 是概率密度函数的积分,对其进行微分可以得到概率密度函数, 这里省略微分的过程,直接给出结果
公式(16.2.6) 就是 Gamma 分布的概率密度函数,其表示随机事件发生 \(k\) 次所需时间 \(t\) 的概率分布。注意,\(f(t)\) 不是具体的时间值,而是时间 \(t\) 的概率分布。 参数 \(k\) 表示事件发生的次数,又被称为形状参数(shape parameter)。 参数 \(\lambda\) 来源于泊松分布,表示随机事件发生的频次,即单位时间发生的平均次数,又被称为速率参数(rate parameter)。
备注
什么是形状参数(shape parameter)?
在概率分布中,按照参数对概率分布函数曲线的影响,可以分为几种。
位置参数(location parameter),影响着图形在 \(x\) 轴上的位置;
尺度参数(scale parameter),控制着图形的拉伸和缩小,可以缩放图形。 尺度参数的倒数称为速率参数(rate parameter),对图形的影响与尺度参数是一样。
形状参数(shape parameter),其既不是位置参数也不是尺度参数(也不是关于这两者的函数)。 形状参数直接影响图形分布的形状,而不是简单地移动分布(如位置参数)或拉伸/缩小分布(如比例参数)。
Gamma 分布的期望和方差分别为:
\(k\) 是事件发生总次数,\(\lambda\) 是事件发生速率, 显然事件发生 \(k\) 次所需要的平均时间就是 \(k/\lambda\) ,这和 Gamma 分布的期望是一致的。
当 \(k=1\) 时,Gamma分布就退化为指数分布:
因此有 \(Gamma(1,\lambda) = Exponential(\lambda)\) 成立,更一般的,如果有 \(n\) 个独立的指数分布 \(Exponential(\lambda)\) 随机变量, 就可以得到一个 Gamma 分布的随机变量 \(Gamma(n,\lambda)\) 。
现在我们来看下形状参数和速率参数分别对概率分布函数的影响是怎样的。 图 16.2.1 展示了形状参数 \(k\) 对概率分布函数的影响, 图 16.2.2 展示了速率参数 \(\lambda\) 对概率分布函数的影响。
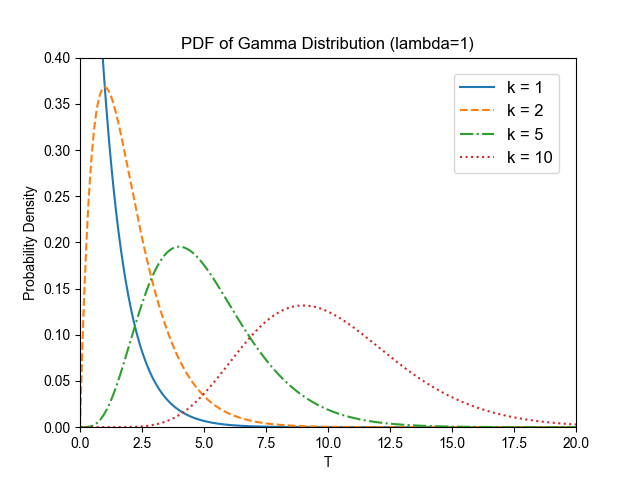
图 16.2.1 Gamma分布不同 \(k\) 值下图形比较¶
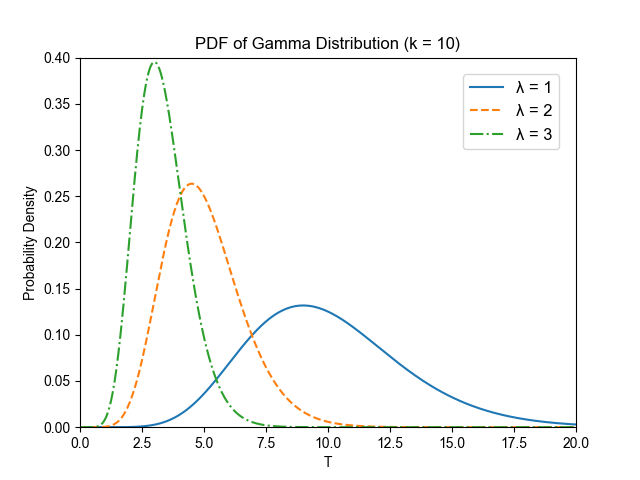
图 16.2.2 Gamma分布不同 \(\lambda\) 值下图形比较¶
通常 Gamma 分布的概率密度函有多种参数化方式, 在计量经济学和其它一些自然科学领域,经常使用形状参数和尺度参数进行参数化表示。
常见参数化方式1:
令参数 \(\alpha=k\) 表式形状参数,参数 \(\beta=1/\lambda\) 表示尺度参数, 服从 Gamma 分布的随机变量 \(X\) 的概率密度函数为
这种形式常见于计量经济学和其它一些自然科学领域。
这种形式下,Gamma 分布的期望和方差为别为
常见参数化方式2:
令参数 \(\alpha=k\) 表式形状参数,参数 \(\beta=\lambda\) 表示尺度参数,
这种方式下, 尺度参数 \(\beta\) 和 公式(16.2.9) 是倒数关系,这只是不同的参数化方法而已,
二者是等价的,这时 Gamma 分布的概率分布函数写成
此时的期望和方差为别为
16.3. Gamma 回归模型¶
在GLM中,Gamma模型用于响应数据只能取大于或等于0的连续值数据进行建模。
Gamma 分布是是一个双参数分布,包含形状参数 \(\alpha\) 和尺度化参数 \(\beta\) ,形状参数 \(\alpha\) 表示事件的发生次数,尺度化参数 \(\beta\) 表示平均一次事件发生需要的时间。 二者的乘积 \(\mu=\alpha \beta\) 就是事件发生 \(\alpha\) 次所需的平均时间, 即 Gamma 分布的期望值(均值)。
当把 Gamma 分布作为 GLM 家族的成员时, 需要把 \(\alpha\) 看做一个已知的常量, 也就是人为给 \(\alpha\) 设置一个常数,并且对于所有观测样本都是一样的值。 通常这个值一个经验值,需要根据观测数据分布情况
GLM中指数族分布的标准形式为
现在我们把 Gamma 分布的概率密度函数转化成上述指数族分布的标准形式, 首先,从上文已知 Gamma 分布的期望为 \(\mu=\alpha \beta\) 。令 \(\phi = 1/\alpha\) ,则有 \(\alpha = 1 / \phi ,\beta=\mu / \alpha=\mu \phi\) ,代入到 公式(16.2.9) 可得
和 公式(16.2.9) 对比下,可以直接得到各个重要组件的形式。
显然 Gamma模型的标准连接函数就是倒数函数, \(\eta=g(\mu) = \theta= 1/\mu\) 。 现在我们看下 Gamma 分布的期望和方差函数。
注意, \(b''(\theta)\) 是方差函数,体现的是方差和均值的关系, 显然 Gamma 分布的方差是和其均值相关的 ,Gamma 分布的方差为:
最后我们整理一下 Gamma 模型的一些关键组件。
16.4. 参数估计¶
16.4.1. 似然函数¶
概率分布函数的指数族形式 公式(16.3.2) ,直接去掉底数就得到了其对数似然函数。
根据 公式(8.1.12) ,标准连接函数的Gamma模型的似然函数的一阶偏导为
16.4.2. IRLS¶
只需要给出 \(W\) 和 \(Z\) 的计算等式就可以应用IRLS算法。
16.4.3. 拟合优度¶
Gamma模型的偏差统计量为
Gamma模型的皮尔逊卡方统计量为
16.5. 其他连接函数¶
16.5.1. 对数 Gamma 模型¶
前面我们提到,在给定一组特定的解释变量或预测变量的情况下,倒数链接估计模型响应的每单位速率。 对数链接的 Gamma 表示响应的对数率。 该模型规范与指数回归相同。 当然,这样的规范估计数据呈负指数下降。 但是,与生存分析中发现的指数模型不同,我们不能将对数伽马模型用于审查数据。 但是,我们看到未经审查的指数模型可以符合GLM规范。 我们将其保留到本章末尾。
对数伽玛模型,与它的对等模型一样,用于响应大于0的数据。几乎在每个学科中都可以找到示例。 例如,在健康分析中,通常可以使用对数伽玛回归来估算住院天数(LOS), 因为住院天数总是被约束为正数。 LOS数据通常使用泊松或负二项式回归进行估计,因为LOS的元素是离散的。 但是,当存在许多LOS元素(即许多不同的LOS值)时,许多研究人员发现伽马或高斯逆模型是可以接受的并且是更可取的。
在GLM之前,通常使用对数转换响应的高斯回归来估计现在使用对数伽马技术估计的数据。 尽管两种方法的结果通常相似,但对数伽马技术不需要外部转换,更易于解释,并带有一组残差,可用于评估模型的价值。 因此,对数伽马技术正在曾经使用过高斯技术的研究人员中得到越来越多的使用。
对数 gamma 模型是值其连接函数是对数函数,其响应函数(反链接)是指数函数。
对数连接函数的一阶导数是 \(g'(\mu)=1\mu\) , 可以轻松的使用IRLS算法进行参数估计。 但是由于对数连接函数表示规范连接函数, IRLS算法的估计量和ML算法的估计量有不同的标准误差(standard errors)。 但是,除了极端情况外,标准误差的差异通常很小。 在较大数据集时,使用不同的估算方法通常不会产生任何推断差异。
16.5.2. 恒等(identity) Gamma 模型¶
恒等连接函数 \(\eta=\mu\) ,假设 \(\mu\) 和 \(\eta\) 之间存在一一对应的关系。 高斯模型的规范链接就是恒等函数,但是Gamma模型中恒等函数不是规范链接。
在同一模型家族的不同链接之间进行选择有时可能很困难。 McCullagh和Nelder(1989)支持最小偏差的方法。 他们还检查残差以观察拟合的紧密度以及标准化残差本身的正态性和独立性。 在此示例中,我们有两个我们要比较的非规范链接:对数和恒等链接。 在其他因素都相同的情况下,最好选择偏差最小的模型。
我们也可以使用其他统计检验方法来评估链接之间的差异, 比如BIC和AIC,这些检验值较低的模型是更好一些的。 关于BIC,如果两个模型的BIC之间的绝对差小于2, 则两个模型的差异是比较小的。 2和6之间差值时,两个模型之间就有了一定的区别。 而6和10之间的差值,则说明两个模型有了明显的区别。 绝对差值大于10,那就肯定是BIC值较小的那个模型更好了。