3. 推断与检验¶
上一章我们介绍了统计推断中应用最广泛的最大似然估计, 然而当我们得到一个参数估计值后, 我们期望知道这个估计值靠不靠谱,它与参数的真实值又相差多少, 本章我们讨论如何评价一个参数估计值的好坏。 在正式讨论估计值评价方法之前,需要先熟悉统计推断中一些基本知识, 比如充分统计量、费歇尔信息、抽样分布等等, 要理解后面的内容需要对这些基础概念十分熟悉才行, 希望读者能花些精力理解这些基础知识, 如果仅靠本书的内容还不能理解, 请辅助参考其它概率与统计学的资料。
3.1. 统计量和充分统计量¶
我们首先讨论统计量以及充分统计量的概念。
假设有一个独立同分布的观测样本集 \(\mathcal{D} = \{x_1,x_2,\dots,x_N\}\) , 样本集中的样本都是从同一个概率分布 \(P(X;\theta)\) 采样得到,其中 \(\theta\) 是这个分布的未知参数,参数空间为 \(\Theta\) 。 上一章已经讲过,我们可以使用最大似然估计参数 \(\theta\), 并且参数的估计值是一个关于样本的函数 \(\hat{\theta} = g(\mathcal{D})\) 。 在统计学中,把观测样本的函数称为 统计量。
- 统计量¶
正式地,任意观测样本的实值函数 \(T=g(\mathcal{D})\) 都称为一个 统计量(statistic) 。 一个统计量就是一个关于样本集的函数(允许是向量形式的函数),在这个函数中不能有任何未知参数 。 比如,样本的均值 \(\bar{x}=\frac{1}{N}\sum_i^N x_i\) ,最大值 \(max(\mathcal{D})\) , 中位数 \(median(\mathcal{D})\) 以及 \(f(\mathcal{D})=4\) 都是统计量。 但是 \(x_1+\mu\) ( \(\mu\) 是未知参数)就不是统计量。
参数估计值是统计量
在进行参数估计时,我们能利用的只有观测样本集,因此观测样本是我们进行参数估计的唯一信息源。 也就是说,我们能利用的有关参数的所有可用信息都包含在观察样本中。 因此,我们获得的参数估计量始终是观测值的函数,即参数估计量是统计量。 从某种意义上讲,该过程可以被认为是“压缩”原始观察数据:最初我们有N个数字, 但是经过这个“压缩”之后,我们只有1个数字 。 这种“压缩”总是使我们失去有关该参数的信息,决不能使我们获得更多的信息。 最好的情况是,该“压缩”结果包含的信息量与N个观测值中包含的信息量相同, 也就是该“压缩”结果包含的信息量已经是关于参数的信息的全部。
统计量是随机变量
观测样本集 \(\mathcal{D}\) 可以看成是 \(N\) 个服从相同概率分布的随机变量的独立采样, 每重新进行一次采样,都会得到不同的样本集,也就是说样本集 \(\mathcal{D}\) 本身也是随机(不同采样得到不一样的值)的,因此样本集 \(\mathcal{D}\) 可以看做是由 \(N\) 个随机变量组成,记作 \(\mathcal{D}=\{X_1,X_2,\cdots,X_N\}\) ,大写表示随机变量 。 统计量作为样本集 \(\mathcal{D}\) 的函数,也就相当于是 \(N\) 个随机变量的函数。
在第一章我们就讲过, 随机变量的函数仍然是一个随机量,那么作为样本函数的统计量自然就是随机变量,而参数估计值是统计量, 因此参数估计值是一个随机变量,所以有时可以称参数估计值为参数估计量。
充分统计量
假设有一个统计量 \(T(\mathcal{D})\) ,并且 \(t\) 是 \(T\) 的一个特定值, 如果在给定 \(T=t\) 的条件下,我们就能计算出样本的联合概率 \(P(X_1,X_2,\dots,X_N|T=t)\) , 而不再依赖参数 \(\theta\) ,这个统计量就是 充分统计量(sufficient statistic) 。
换种说法,在给定充分统计量 \(T=t\) 条件下,就能确定参数 \(\theta\) 的值,而不再需要额外的信息, 我们可以设想只保留 \(T\) 并丢弃所有 \(X_i\),而不会丢失参数的任何信息! 从上面的直观分析中,我们可以看到充分统计量“吸收”了样本中包含的有关 \(\theta\) 的所有可用信息。 这个概念是R.A. Fisher在1922年提出的。
充分性的概念是为了回答以下问题而提出的: 是否存在一个统计量,即函数 \(T(X_1,\dots,X_N)\) ,其中包含样本中有关 \(\theta\) 的所有信息? 如果这样,则可以将原始数据减少或压缩到该统计信息而不会丢失信息。 例如,考虑一系列成功概率未知的独立伯努利试验。 我们可能有一种直觉的感觉,成功次数包含样本中有关 \(\theta\) 的所有信息, 而成功发生的顺序没有提供有关 \(\theta\) 的任何其他信息。 对于高斯分布,(样本)期望和(样本)协方差矩阵就是它的充分统计量,因为如果这两个参数已知, 就可以唯一确定一个高斯分布,而对于高斯分布的其他统计量,例如振幅、高阶矩等在这种时候都是多余的。
在很多问题中,参数的最大似然估计量就是一个充分统计量 ,比如,伯努利实验的参数估计量就是一个充分统计量 \(\hat{\theta}_{ML}=\frac{1}{N}\sum_{i=1}^N X_i=\bar{X}\) 。 同样,贝叶斯参数估计量也是一个充分统计量。最大似然估计量和贝叶斯估计量都是充分统计量的一个函数, 它们”吸收”了观测样本中关于参数的所有有用信息。
备注
根据统计量的定义:样本的一个函数可以称为统计量,样本的求和 \(\sum_{i=1}^N X_i\) , 样本的均值 \(\frac{1}{N}\sum_{i=1}^N X_i\) 都可以称为统计量。 所以,似然估计量 \(\hat{\theta}_{ML}=\frac{1}{N}\sum_{i=1}^N X_i\) 可以整体看做一个充分统计量(样本均值统计量), 也可以看做是充分统计量(求和统计量) \(\sum_{i=1}^N X_i\) 的一个函数。
3.2. 抽样分布¶
在统计学中,把需要调查或者研究的某一现象或者事物的全部数据称为统计总体,或简称 总体(population)。 比如,我们要研究中国人的身高分布,那么全国14亿人的身高数据就是总体(population), 这14亿身高数据所属的数据分布称为 总体分布 (population distribution), 其中每一个人的身高数据,即单个数据称为个体(individual)。 然而在实际中,我们不可能得到14亿的全部数据,也就是 总体数据通常是无法得知的 。 这时,可以选择抽样(sampling),即从总体当中随机抽取出部分个体,然后得到这部分抽样个体的数据, 一次抽样的结果称为一份样本(sample)。 比如,从14亿的人群中随机抽取出1万的个体,然后去测量这1万人的身高数据, 这样就得到了一份包含1万个数据的样本,样本的容量(sample size),或者说样本的大小,是1万。 注意样本(sample)和个体(individual)的区别,样本(sample)是一次抽样的结果,包含多个个体(individual)数据, 一份样本中包含的个体数据的数量称为本容量(sample size)。
随机变量抽样样本的函数称为统计量,统计量也是随机变量。 既然是随机变量,那统计量也定然会服从某种概率分布, 在统计学中,把统计量的概率分布统称为抽样分布(sample distribution)。 抽样分布也称统计量分布、随机变量函数分布,是指样本统计量的分布。 注意,抽样分布并不是某个具体的概率分布,而是一个统称, 其实就是”抽样样本的函数(统计量)的概率分布”的简称, 比较常见的抽样分布是正态分布、学生t分布、卡方分布、F分布等, 一个统计量具体是哪种抽样分布,这要取决于总体分布(抽样样本所属的概率分布)是什么以及统计量的函数是什么。
假设需要调查国人的身高情况,想要知道全国人民身高的均值和方差。 但是显然不可能测量得到全国人民的身高数据,然后计算得到均值和方差。 在统计学上,通常通过抽样解决这类问题。 根据经验,我们假设全国人民的身高数据服从正态分布, 记为 \(X \sim N(\mu,\sigma^2)\) , 变量 \(X\) 就是总体正态变量, \(\mu\) 和 \(\sigma^2\) 分别表示总体的期望和方差。 然后从总体中,随机抽取一份包含1万个个体的样本,并且依次测量出这1万个个体的身高数据, 记为 \(\mathcal{D}=\{X_1,X_2,\dots,X_N \},N=100000\) , 这就相当于从总体正态分布中取得一个独立同分布的采样。 现在我们要利用这个样本估计出总体的期望参数 \(\mu\) 和方差参数 \(\sigma^2\) 。
显然我们可以应用最大似然估计得到参数的估计值,这里我们直接使用 节 2.1.3 的结论, 期望参数 \(\mu\) 和方差参数 \(\sigma^2\) 的最大似然估计量分别是
显然参数的最大似然估计值是一个样本的函数(统计量),因此它是一个随机变量。 现在我们看下参数估计量 \(\hat{\mu}\) 和 \(\hat{\sigma}^2\) 的抽样分布分别是什么。
3.2.1. 正态分布¶
我们先看期望参数估计量的抽样分布, 总体正态分布的期望(均值)参数的似然估计量 \(\hat{\mu}\) 就等于样本的均值统计量。
抽样样本集中每一条样本 \(X_i\) 都是正态分布随机变量, 根据第一章讲的正态分布的性质: 多个正态随机变量的线性组合结果仍然是一个正态随机变量 , 显然估计量 \(\hat{\mu}\) 是 服从正态分布的 。 并且根据期望的计算性质,可知估计量的均值为
参数估计量 \(\hat{\mu}\) 的期望就等于总体的期望 \(\mu\) ,这和我们的直观认知是一致的。 现在我们看下参数估计量 \(\hat{\mu}\) 的方差计算
最终估计量 \(\hat{\mu}\) 的抽样分布是均值为 \(\mu\),方差为 \(\sigma^2/N\) 的正态分布, 记作
也可以记作
通常会把这个统计量称为 \(Z\) 统计量,\(Z\) 统计量是服从标准正态分布的, 但是注意,要想得到这个统计量需要总体的标准差 \(\sigma\) 是已知的才行。
3.2.2. 学生t分布¶
上一节我们讲到总体正态分布的期望估计量(样本均值统计量)的抽样分布是正态分布 \(N(\mu,\frac{\sigma^2}{N})\) ,抽样分布的方差是 \(\frac{\sigma^2}{N}\)。 其中含有总体的方差,然而很多时候总体方差 \(\sigma^2\) 是未知的, 此时需要找一个总体方差 \(\sigma^2\) 的替代值。
显然可以使用方差估计值(样本的方差统计量)作为总体方差 \(\sigma^2\) 的近似替代, 样本的方差为
根据 节 1.8.7 讲的t-分布的定义, 如下统计量 \(T\) 是服从自由度为 \(N-1\) 的t-分布。
可以对比下 公式(3.2.6) 和 公式(3.2.8) 的区别, 当总体方差未知的时候,服从标准正态分布的 \(Z\) 统计量无法得到, 此时可以使用 \(T\) 统计量作为替代。
但是如果样本数量超过 \(30\),就可以不使用 \(T\) 统计量, 而是直接使用 \(Z\) 统计量。 在 节 1.8.7 节讲过, 当样本数量超过 \(30\) 的时候,t分布和标准正态分布基本是重合的, 两者没啥区别,也就是说此时使用方差估计值(样本方差)作为 \(Z\) 统计量中总体方差的替代也是可以。即当样本数量 \(N>30\) 时, 如下 \(Z\) 统计量的抽样分布近似成立。
3.2.3. 卡方分布¶
现在看下方差估计量 \(\hat{\sigma}^2\) 的抽样分布, 总体正态分布 \(\mathcal{N}(\mu,\sigma^2)\) 方差参数的无偏计量为
方差估计量(样本方差)的抽样分布是和卡方分布的相关的,有如下(渐近)分布成立。
证明过程如下:
根据卡方分布的定义:多个标准正态分布的平方和服从卡方分布,可知如下变量 \(Z\) 是自由度为 \(N\) 的卡方随机变量
分子部分加上同时减去一个 \(\bar{X}\),\(Z\) 保持不变。
然后把平方展开
上述等式右边的最后一项是 \(0\)。
因此 \(Z\) 简化成
然后可以把方差的估计量 公式(3.2.10) 代入到等式中。
移项可得
又因为有 \(\bar{X} \sim \mathcal{N}(\mu,\sigma^2/N)\),等式右侧的第二项是一个标准正态分布的平方。 显然等式右侧变成一个自由度为 \(N-1\) 的卡方分布。
注意,如果方差估计量用的似然估计量(有偏估计)
卡方统计量就变成
3.3. 极限理论¶
我们已经理解了总体、样本、统计量、抽样分布的概念, 并且知道正态分布的样本均值统计量的抽样分布是正态分布。 抽样样本集 \(\mathcal{D}=\{X_1,X_2,\cdots,X_N\}\) 的另一个相关因子是样本的数量 \(N\) ,正所谓量变引起质变, 本节我们讨论当 \(N\) 极大时样本统计量会呈现出什么性质。
设 \(X_1,X_2,\cdots,X_N\) 为一个独立同分布的随机变量序列, 其公共分布的均值为 \(\mu\), 方差为 \(\sigma^2\)。 定义
为这个随机变量序列之和,本节的极限理论研究 \(S_N\) 以及与 \(S_N\) 相关的变量在 \(N \rightarrow \infty\) 时的极限性质。
由随机变量序列的各项之间的相互独立性可知
显然当 \(N \rightarrow \infty\) 时,\(S_N\) 是发散的,不可能有极限。 但是 样本均值统计量
却不同,经过简单计算可知
当 \(N \rightarrow \infty\) 时, 样本均值统计量 \(M_N\) 的方差趋近于 \(0\) 。方差趋近于 \(0\) 意味着 \(M_N\) 就与 \(\mu\) 特别接近。 这种现象就是大数定律的内容。 按通常的解释,当样本量 \(N\) 很大的时候, 从 \(X\) 抽取的样本平均值 \(M_N\) 就是变量 \(X\) 的平均值 \(\mathbb{E}[X]\) 。这里对 \(X\) 属于哪种概率分布并没有限制,非正态分布也符合这个定律。
下面考虑另一个随机变量,用 \(S_N\) 减去 \(N\mu\), 可以得到零均值随机变量序列 \(S_N - N\mu\), 然后再除以 \(\sigma \sqrt{N}\) , 就得到随机变量序列
易证明
因为 \(Z_N\) 的均值和方差不依赖于样本容量 \(N\) ,所以它的分布既不发散,也不收敛于一点。 中心极限定理 就研究 \(Z_N\) 的分布的渐近性质,并得出结论: 当 \(N\) 充分大的时候,\(Z_N\) 的分布就接近标准正态分布。
3.3.1. 马尔可夫和切比雪夫不等式¶
我们首先介绍一些重要的不等式,这些不等式是大数定律和中心极限定理的基础。 这些不等式使用随机变量的均值和方差去分析事件的概率, 在随机变量 \(X\) 的均值和方差易于计算,但分布不知道或不易计算时, 这些不等式就非常有用。
首先介绍 马尔可夫不等式 。 粗略的讲,该不等式是指,一个 非负 随机变量如果均值很小, 则该随机变量取大值的概率也非常小。 仔细想一想,这句话其实很好理解。
下面介绍 切比雪夫不等式 , 粗略的讲,切比雪夫不等式是指如果一个随机变量的方差非常小的话, 那么该随机变量取远离均值 \(\mu\) 的概率也非常小。 注意的是:切比雪夫不等式并不要求所涉及的随机变量非负。
切比雪夫不等式和马尔可夫不等式都是描述的随机变量 \(X\) 的某部分概率的上界, 切比雪夫不等式比马尔可夫不等式更准确,即由切比雪夫不等式提供的概率的上界离概率的真值更近, 这是因为它利用了 \(X\) 的方差的信息。 当然一个随机变量的均值和方差也仅仅是粗略地描述了随机变量的性质, 所以由切比雪夫不等式提供的上界与精确概率也可能不是非常接近。
3.3.2. 弱大数定律¶
弱大数定律 是指独立同分布的随机变量序列的样本均值,在大样本的情况下,以很大的概率与随机变量的均值非常接近。
下面考虑独立同分布的随机变量序列 \(X_1,X_2,\cdots,X_N\), 它们的公共分布(总体分布)的均值为 \(\mu\), 方差为 \(\sigma^2\)。定义样本均值
则
再运用独立性可得
利用切比雪夫不等式可得
注意,对任意固定的 \(\epsilon >0\),上面不等式的右边在 \(N \rightarrow \infty\) 时趋近于 \(0\), 于是就得到如下的弱大数定律。这里要提到的是: 当 \(X_i\) 的方差无界时,弱大数定律仍然成立, 但是需要更严格而精巧的证明,在此省略。 因此,在下面陈述的弱大数定律中,只需要一个假设,即 \(\mathbb{E}[X_i]\) 是有限的。
弱大数定律是指对于充分大的 \(N\),\(M_N\) 的分布的大部分都集中在 \(\mu\) 的 附近 。 设包含 \(\mu\) 的一个区间为 \([\mu-\epsilon,\mu+\epsilon]\), 则 \(M_N\) 位于该区间的概率非常大。 当 \(N \rightarrow \infty\) 时,该概率为 \(1\)。 当然当 \(\epsilon\) 非常小时,则需要更大的 \(N\), 使得 \(M_N\) 以很大的概率落在这个区间。 弱大数定律的另一个理解就是在 \(N\) 充分大时, \(M_N\) 依概率收敛于 \(\mu\)。
3.3.3. 依概率收敛¶
弱大数定律可以表述为” \(M_N\) 收敛于 \(\mu\) ” 。但是,既然 \(M_1,M_2,\cdots\) 是随机变量序列, 而不是数列,所以这里”收敛”的含义不同于数列的收敛,应该给予更明确的定义 。
根据这个定义,弱大数定律就是说样本均值统计量依概率收敛于总体分布的真值 \(\mu\) 。更一般地,利用切比雪夫不等式可以证明:如果所有的 \(Y_N\) 具有相同的期望,而方差 \(V(Y_N)\) 趋近于 \(0\), 则 \(Y_N\) 依概率收敛于 \(\mu\)。
如果随机变量序列 \(Y_1,Y_2,\cdots\) 有概率质量函数或者概率密度函数,且依概率收敛于 \(a\)。 则根据依概率收敛的定义,对充分大的 \(N\),\(Y_N\) 的概率质量或者密度函数的大部分”质量”集中在 \(a\) 的 \(\epsilon\) 邻域 \([a-\epsilon,a+\epsilon]\) 内。 所以依概率收敛的定义也可以这样描述: 对任意的 \(\epsilon >0\) 和 \(\delta >0\), 存在 \(N_0\),使得对所有的 \(N \geq N_0\) 都有
其中 \(\epsilon\) 称为 精度,\(\delta\) 称为 置信水平。 依概率收敛的定义有如下形式: 任意给定精度和置信水平,在 \(N\) 充分大时 \(Y_N\) 等于 \(a\) 。
3.3.4. 中心极限定理¶
根据弱大数定律,样本均值 \(M_N=(x_1+x_2+\cdots+x_N)/N\) 的分布随着 \(N\) 的增大,越来越集中在真值 \(\mu\) 的邻域内。特别地, 在我们的论证中,假定 \(X_i\) 的方差为有限的时候, 可以证明 \(M_N\) 的方差趋近于 \(0\)。 另一方面,前 \(N\) 项的和
的方差趋近于 \(\infty\), 所以 \(S_N\) 的分布不可能收敛。 换一个角度,我们考虑 \(S_N\) 与其均值 \(N \mu\) 的偏差 \(S_N - N \mu\), 然后乘以正比于 \(1/\sqrt{N}\) 的刻度系数。 乘以刻度系数的目的就是使新的随机变量具有固定的方差。 中心极限定理指出这个新的随机变量的分布趋于标准正态分布。
具体地说,设 \(X_1,X_2,\cdots\) 是独立同分布的随机变量序列, 均值为 \(\mu\), 方差为 \(\sigma^2\)。 定义
经过简单计算可以得到
中心极限定理允许人们可以将 \(Z_N\) 的分布看成正态分布,从而可以计算与 \(Z_N\) 相关的随机变量的概率问题,因为正态分布在线性变换之下仍然是正态分布。 如果把 \(Z_N\) 的分子分母同时除以 \(N\),就可以用均值统计量 \(M_N\) 表示。
再经过一些简单的变换,可以认为均值统计量的极限分布是均值为 \(\mu\) 方差为 \(\sigma^2/N\) 的正态分布。
(3.3.25)¶\[M_N \sim N( \mu,\frac{\sigma^2}{N})\]
中心极限定理对 \(X_i\) 的分布并没有任何要求, 但是 \(X_i\) 的分布多少还是有一点不一样的地方。
当总体分布 \(X_i\) 是正态分布 \(\mathcal{N}(\mu,\sigma^2)\) 时,无论样本 \(N\) 是多少, 均值统计量 \(M_N\) 都服从正态分布 \(\mathcal{N}(\mu,\sigma^2/N)\) 。
当总体分布 \(X_i\) 不是正态分布时,均值统计量 \(\bar{X}\) 渐近服从(极限分布)正态分布 \(\mathcal{N}(\mu,\sigma^2/N)\) , \(N\) 越大越接近正态分布。至于 \(N\) 是多少才行,并没有一个准确的判断方法,这和 \(X_i\) 的分布有关。 \(X_i\) 的分布与正态分布相差越大,需要的 \(N\) 就越大;反之,\(X_i\) 的分布与正态分布越相似,需要的 \(N\) 越小。
中心极限定理是一个非常具有一般性的定理。对于定理的条件, 除了序列为独立同分布的序列之外,还假设各项的均值和方差的有限性。 此外,对 \(X_i\) 的分布再也没有其它的要求。 \(X_i\) 的分布可以是离散的、连续的或是混合的。
这个定理不仅在理论上非常重要,而且在实践中也是如此。 从理论上看,该定理表明大样本的独立随机变量序列和大致是正态的。 所以当人们遇到的随机变量是由许多影响小但是独立的随机因素的总和的情况, 此时根据中心极限定理就可以判定这个随机量的分布是正态的。 例如在许多自然或工程系统中的白噪声就是这种情况。
从应用角度看,中心极限定理可以不必考虑随机变量具体服从什么概率分布,避免了概率质量函数和概率密度函数的繁琐计算。 而且,在具体计算的时候,人们只需均值和方差的信息以及简单查阅标准正态分布表即可。
3.3.5. 强大数定理¶
强大数定律与弱大数定律一样,都是指样本均值统计量收敛于真值 \(\mu\)。 但是它们强调的是不同的收敛类别, 下面是强大数定律的一般陈述。
强大数定律与弱大数定律的区别是细微的,需要仔细说明。 弱大数定律是指 \(M_N\) 显著性偏离 \(\mu\) 的事件的概率 \(P(|M_N -\mu|)\geq \epsilon\) 在 \(N \rightarrow \infty\) 时区域 \(0\)。 但是对任意有限的 \(N\),这个概率可以是正的(大于零)。 所以可以想象的是,在 \(M_N\) 这个无穷的序列中, 常常有 \(M_N\) 显著偏离 \(\mu\)。 弱大数定律不能提供到底有多少会显著性偏离 \(\mu\),但是强大数定律却可以。 根据强大数定律, \(M_N\) 以概率 \(1\) 收敛于 \(\mu\)。 这意味,对任意的 \(\epsilon >0\),偏离 \(|M_N-\mu|\) 超过 \(\epsilon\) 的只能发生有限次。
强大数定律中的收敛与弱大数定律中的收敛是两个不同的概念,现在给出以概率 \(1\) 收敛的定义。
类似于前面的讨论,我们应该正确理解以概率 \(1\) 这种收敛类型, 这种收敛也是在由无穷数列组成的样本空间中建立的: 若某随机变量序列以概率 \(1\) 收敛于常数 \(c\), 则在样本空间中,全部的概率集中在满足极限等于 \(c\) 的无穷数列的子集上。 但这并不意味其他的无穷序列是不可能的,只是他们是非常不可能的,即他们的概率是 \(0\)。
3.4. 似然估计量¶
前几节我们已经把评价一个参数估计量所需的基础知识讨论的差不多了的, 参数估计量一定是一个关于样本的函数, 而样本的函数定义为统计量, 因此参数估计量是统计量。 统计量也是一个随机变量, 统计量的分布统称为抽样分布。 大数定律给出了均值统计量的极限收敛性质, 中心极限定理进一步强化,给出了均值统计量的极限分布。 概率分布的均值参数的最大似然估计量就等于样本的均值估计量, 因此我们可以运用中心极限定理对均值参数的似然估计量进行分析。
设 \(X_1,X_2,\cdots\) 是独立同分布的随机变量序列,亦可以看做是某个总体变量 \(X\) 的独立同分布的观测样本。 \(\theta\) 是变量 \(X\) 所属分布的一个参数, 它的最大似然估计量记作 \(\hat{\theta}\), 假设参数的真实值是 \(\theta_{true}\)。
我们知道估计量 \(\hat{\theta}\) 是一个随机量,它不能精确等于参数真实值 \(\theta_{true}\)。 但是如果当样本数量 \(N\) 足够大时,估计量 \(\hat{\theta}\) 可以依概率收敛于参数的真实值 \(\hat{\theta}\), 那么我们就说这个估计量是 一致性估计量 。
在统计学中,一致估计量(Consistent Estimater)、渐进一致估计量,亦称相合估计量、相容估计量。 其所表征的一致性或(相合性)同渐进正态性是大样本估计中两大最重要的性质。随着样本量无限增加, 估计误差在一定意义下可以任意地小。也即估计量的分布越来越集中在所估计的参数的真实值附近, 使得估计量依概率收敛于参数真值。 这里定义的一致性称弱相合性。如果将概率收敛的方式改为以概率 \(1\) 收敛就称为强相合性。
为什么是 依概率 收敛,而不是 确定性 收敛? 因为参数估计量本身是一个随机变量,服从某种概率分布,只能是以某种概率得到某个确定性的值, 所以这里是依概率收敛到真实值。 一致性是对参数估计的基本要求,一个参数估计要是不满足一致性基本无用。
一致性估计量是 依概率 收敛到真实值的,并不是一定收敛到真实值, 所示我们实际上得到的参数估计量和真实值之间还是会存在一定误差的。 我们需要对这个误差进行量化评估,以便能评估一个估计量的好坏。
最直接的误差就是估计量和真实值之间的差值, \(d=\hat{\theta}-\theta\) , 但是差值 \(d\) 有正有负,不易使用, 因此我们采用它的平方, 定义参数估计量和参数真实值之间的平方误差(Squared Error,SE)为
其中 \(\hat{\theta}\) 是一个随机量,导致 SE 也是一个随机量,
我们用它的期望值作为最终的评价误差,平方误差的期望称之为均方误差(mean square error,MSE)
。
显然一个参数估计量和参数真实值之间的误差由两部分组成:估计量的方差 和 偏差 , 其中方差部分是估计量的方差,不是观测变量 \(X\) 的方差。 两部分都是非负的, 因此一个好的估计量要求两部分都必须小。
3.4.1. 估计量的偏差与方差¶
一个估计量的偏差(bias)被定义成估计量的期望和参数真实值之间的差值,
当偏差为 \(0\) 时,就称这个估计量是 无偏估计量。
我们不可能指望作为随机量的估计量正好和未知的参数真值相等,因此估计误差一般非零。 另一方面,对于 \(\theta\) 所有可能的取值,如果平均估计误差是零,则得到一个无偏的估计量。 渐进无偏只需要随着观测样本数量 \(N\) 的增加,估计量变得无偏即可。
除了偏差,我们还对误差中方差部分的大小感兴趣, 现在我们看下估计量的方差部分, 估计量的方差也是存在下界的,这可以通过一个定理给出。
其中分子部分是估计量的期望对参数真实值的一阶导的平方, 如果一个估计量是无偏估计,那么有 \(\mathbb{E}[\hat{\theta}]=\theta_{\text{true}}\) ,这时分子就等于 \(1\) 。
因此 对于无偏估计量,公式(2.7.20) 可以简化为:
\(I(\theta)\) 是费歇尔信息(Fisher-Information)矩阵。
根据 CRLB 定理,可以看出一个估计量的方差是存在下界的,
并且对于无偏估计量,估计量的方差的最小值是费歇尔信息的倒数,
显然当一个估计量的方差为下界时,这个估计量是最稳定的。
通常会用如下方式衡量一个 无偏估计量 的 有效性(efficiency),
当 \(\mathcal{E}(\hat{\theta})=1\) 时,称此估计量为有效估计(efficient estimator)。
估计量的均方误差由方差和偏差组成,最好的估计量应该是偏差和方差都尽可能的小,偏差最小为无偏估计, 所以我们定义出最小方差无偏估计。
最后我们总结下,
如果估计量依概率收敛于参数真值,则称这个估计量具有相合性,或者说一致性。
如果估计量的期望等于参数真值,则这个估计量是无偏估计。
对于无偏估计量,估计量的方差的最小值是费歇尔信息的倒数。
3.4.2. 信息量¶
在参数估计问题中,我们从目标概率分布的观测样本中获取有关参数的信息。 这里有一个很自然的问题是:数据样本可以提供多少关于未知参数信息? 本节我们介绍这种信息量的度量方法。 我们还可以看到, 该信息量度可用于查找估计量方差的界限, 并可用于近似估计从大样本中获得的估计量的抽样分布, 并且如果样本较大,则进一步用于获得近似置信区间。
假设有一个随机变量 \(X\) ,其概率质量(密度)函数为 \(P(X;\theta)\) , \(\theta\) 是模型未知参数,并且其值未知。 概率质量(密度)函数描述了在给定 \(\theta\) 时, 获取一个 \(X\) 的观测值的概率。 这里我们先看只有一条观测样本的情况,稍后再说有多条观测样本的情况。
随机变量 \(X\) 单条观测样本 对数似然函数为
当利用最大似然估计进行参数估计时,我们需要求对数似然函数的一阶偏导数
其中 \(P'(X;\theta)\) 表示函数 \(P(X;\theta)\) 关于 \(\theta\) 的一阶导数,同理, 符号 \(P''(x;\theta)\) 表示二阶导数。 如果参数 \(\theta\) 是一个标量参数,关于参数的一阶导数和二阶导师也是一个标量。 如果参数 \(\theta\) 是一个参数向量,关于参数的一阶偏导数就是一个向量,二阶偏导数是一个矩阵。
\(S(\theta)\) 是对数似然函数的一阶导数,一阶导数描述的是函数在这一点的切线的斜率, 导数越大切线斜率越大,所以 \(S(\theta)\) 表示的是对数似然函数在某个 \(\theta\) 值时模型的敏感度(sensitive)。
\(S(\theta)\) 是关于 \(X\) 的一个函数, 所以 \(S(\theta)\) 也是一个随机变量, 我们可以研究它的期望与方差。 首先来看一下 \(S(\theta)\) 的期望, 在开始之前,先给出有关积分计算的一些技巧。
一个函数的积分和求导是可以互换的,并且概率质量(密度)函数的积分一定是等于 \(1\) 的, 所以有如下等式成立。
类似地有:
\(S(\theta)\) 关于样本变量的期望一定是等于0的, 结合 公式(2.6.4) 可以推导出 \(S(\theta)\) 的期望为:
\(S(\theta)\) 的二阶矩(second moment),也就是其方差(Variance),被称为 Fisher information,
中文常翻译成费歇尔信息,
通常用符号 \(I(\theta)\) 表示,
\(I(\theta)\) 是一个方阵,通常称为信息矩阵(information matrix)。
实际上, \(I(\theta)\) 和对数似然函数的二阶导数的期望值是有关系的, 我们先来看下对数似然函数的二阶导数, 二阶导数可以在一阶导数的基础上再次求导得到。
然后我们看下对数似然函数二阶导数的期望值:
因此,Fisher information 就等于对数似然函数二阶导数的期望的负数。
但参数 \(\theta\) 是一个参数向量时,对数似然函数的二阶偏导数就是一个矩阵(方阵), 这个二阶偏导数矩阵称为 海森矩阵(Hessian matrix), 通常用符号 \(H\) 表示, 因此 \(I(\theta)\) 经常也被表示成海森矩阵的期望的负数, 当然此时 \(I(\theta)\) 也是一个矩阵,称为 信息矩阵(information matrix) 。
我们看到,无论是通过 score function 的方差计算,还是通过 Hessian 矩阵计算,
\(I(\theta)\) 都是一个期望值,所以经常被称为期望化信息(expected information)。
信息量 \(I(\theta)\) 是关于随机变量 \(X\) 的期望的函数,
已经对 \(X\) 求了期望,所以信息量 \(I(\theta)\) 最终的表达式中不再有随机变量(样本) \(X\)
,它仅仅是一个关于参数 \(\theta\) 的函数。
以上单条观测样本的信息量称为单位费歇尔信息量(unit Fisher information), 如果有 \(N\) 个独立不同分布的 \(N\) 条独立观测样本,它们的信息量就是 \(N\) 条单位信息量的求和。 如果有 \(N\) 条独立同分布的观测样本,它们的信息量就是 \(N\) 倍的单位信息量。 因为单位信息量是变量的期望,与具体的观测样本无关的,所以当有多条观测样本时,累加就可以了。
对于独立同分布的观测样本集 \(\mathcal{D}=\{X_1,X_2,\cdots,X_N\}\) ,它的信息量为
\(I_{\mathcal{D}}(\theta)\) 是正比于 \(N\) 的,也就是说样本越多,我们的到关于参数的信息量就越大。
Fisher 信息是一种测量可观测随机变量 \(X\) 携带其概率所依赖的未知参数 \(\theta\) 的信息量的方式。
Fisher 是 score function (似然函数一阶偏导数)方差,也是似然函数二阶偏导数期望的负数,
Fisher 信息越大似然函数的曲线越尖锐,越容易得到参数的最优解。
根据 CRLB 定理,基于独立同分布观测样本 \(\mathcal{D}\) 的无偏参数估计量的方差的最小值为
从这个也可以看出,当 Fisher 信息越大的时候,参数估计量的方差越小,方差越小自然就容易得到一个接近参数真值的估计值。
同时它是正比于样本数量 \(N\) 的,意味着随着样本的增加,估计量的方差越来越小。
在 Fisher 信息量的实际应用中,当需要计算一个独立同分布的观测样本对于参数的信息量 \(I_{\mathcal{D}} (\theta)\)
时,如果按照上面讲的求了观测变量的期望,那么
此时就称 \(I_{\mathcal{D}} (\theta)\) 是期望(expected)信息(矩阵)。 也就是不求期望,直接就按照观测样本值计算, 此时得到的就是观测(observed)信息(矩阵)。 使用期望信息矩阵和观测信息矩阵分别计算出的估计量的方差会有些差别, 这在之后的广义线性模型的内容中会用到。
3.4.3. 最大似然估计的特性¶
现在我们来看下最大似然估计量具有哪些特点,首先回顾一下分布的均值参数和方差参数的最大似然估计量。
已知随机变量 \(X\) 的期望参数为 \(\mu\),方差参数为 \(\sigma^2\), 两个参数的似然估计量分别记作 \(\hat{\mu}_{ML}\) 和 \(\hat{\sigma}^2_{ML}\) 。
均值参数的似然估计量
均值参数的最大似然估计量就等于样本的均值统计量,
并且估计量 \(\hat{\mu}\) 的期望和方差分别为
显然,对于均值参数的似然估计量有
根据弱大数定律,它相合估计,或者说一致性估计。
它是无偏估计量,它的偏差为 \(0\) ,因此它的均方误差是 \(MSE=\sigma^2/N\) 。
它的方差符合
CRLB的下界,因此它是最小方差无偏估计,或者说是有效估计。根据中心极限定理,它有 渐近正态性(asymptotic normality) ,其渐进服从正态分布 \(N(\mu,\frac{\sigma^2}{N})\) 。
方差参数的似然估计量
随机变量 \(X\) 的方差参数的似然估计量就是样本的方差,即
现在我们也来看下方差估计量的期望值,在计算前,先给出如下几个事实。
估计量 \(\hat{\sigma}^2_{ML}\) 的期望为
可以看到 方差似然估计量的期望不等于方差参数真值,因此它是一个有偏估计量。 但是当 \(N \rightarrow \infty\) 时,它们是相等的,因此 方差似然估计量是渐近无偏的, 同时它也是也是渐近正态性的。
虽然方差的似然估计量是有偏的,但是可以做一个简单的变换得到一个无偏的估计量, 显然只需要乘上 \(N/(N-1)\) 即可。
当样本数量 \(N\) 足够大时 \(\hat{\sigma}^2_{\text{无偏}}\) 与 \(\hat{\sigma}^2_{ML}\) 其实没有太大的区别。
最大似然估计还有一个特别的性质,它遵循 不变原理: 如果 \(\hat{\theta}\) 是 \(\theta\) 的最大似然估计, 那么对于任意关于 \(\theta\) 的一一映射函数 \(h\), \(H=h(\theta)\) 的最大似然估计是 \(h(\hat{\theta})\) 。对于独立同分布的观测,在一些适合的假设条件下,最大似然估计量是相合的或者说一致的。
另一个有趣的性质是当 \(\theta\) 是标量参数的时候,在某些合适的条件下, 最大似然估计量具有 渐近正态 性质。 特别地,可以看到 \((\hat{\theta}-\theta)/V(\hat{\theta})\) 的分布接近标准正态分布。 因此,如果我们还能够估计出 \(V(\hat{\theta}\) 就能进一步得到基于正态近似的误差方差估计。 当 \(\theta\) 是向量参数,针对每个分量都可以得到类似结论。
渐近正态性对应着中心极限定理,最大似然估计是满足渐近正态性的。 似然估计量不仅是渐近服从正态分布,而且是以参数真实值为期望的正态分布, 这表明似然估计量依概率(正态分布)收敛于参数的真实值,这符合一致性的定义。 显然极大似然估计是一致性估计。 由于似然估计是一致性估计,似然估计量是渐近收敛于参数真实值的,也就是估计量的偏差渐近为 \(0\), 因此可以得出似然估计量是 渐近无偏估计 。
我们知道估计量的 MSE 是由偏差和方差组成的( 公式(2.7.2) ),无偏性是对估计量的偏差的评价,
而估计量的方差影响着估计值的稳定性,方差越小估计量就越稳定,
并且最大似然估计量的方差符合 CRLB 的下界,就等于费歇尔信息的倒数,
如果 \(\theta\) 是参数向量,估计量的方差为协方差矩阵,
此时费歇尔信息 \(I(\theta)\)
为信息矩阵(Information matrix)。
这里我们省略证明过程,有兴趣的读者可以参考其他资料。
显然似然估计不仅仅是渐近无偏估计,而且估计量的方差就等于 CRLB 定理的下界,
因此似然估计量是不仅仅是有效估计量,而是其最小方差无偏估计(Minimum Variance Unbiased Estimator,MVUE),
并且我们可以通过 \(I(\theta)\) 量化衡量MLE估计量的方差。
当我们用最大似然估计出一个参数的估计值后,我们期望能量化评估出这个参数估计值的好坏, 大家常用的方法是计算观测值的误差:
这种方法衡量的是整个模型的预测效果,并不能衡量出参数的估计值和参数的最优值之间的误差, 我们已经知道最大似然估计是无偏估计,那么最终最大似然估计量的误差就可以用如下公式衡量:
\([I(\theta)]^{-1}\) 是协方差矩阵,其对角线元素是每个参数方差,开根号后得到每个参数的标准差。
最后我们总结下最大似然估计拥有的特性:
最大似然估计量符合大数定律,它是一致性(consistency)估计,或者数相合估计。
由于满足一致性,渐近收敛于参数真实值,渐近偏差为 \(0\),因此它满足渐近无偏性(unbiased)。
根据中心极限定理,它有 渐近正态性(asymptotic normality) ,其渐进服从正态分布 \(N(\mu,\frac{\sigma^2}{N})\) 。
最大似然估计量的方差符合
CRLB定理的下限,所以是有效估计(Efficient Estimator),并且是最小方差无偏估计。
最大似然估计量这些特性都是 渐近的,即当观测样本数量 \(N\) 足够大时才能显现出来, 好处是对观测变量所属的分布没有任何要求,即不管观测变量服从什么概率分布,最大似然估计都有这些渐近特性。 有一个例外是,如果观测变量的概率分布是正态分布,则 不再是渐近的,而是 精确的。
3.5. 置信区间¶
在统计学中,由样本数据估计总体分布所含未知参数的真实值,所得到的值,称为估计值。 最大似然为我们提供了一个利用样本估计总体未知参数的良好方法, 通过上一节的内容,我们已经知道最大似然估计量拥有非常好的性质, 多数情况下,能为我们提供一个良好的参数估计值。 我们把这种估计结果使用一个点的数值表示“最佳估计值”方法,称为点估计(point estimation)。
我们知道估计量是一个随机变量,通过现有的样本算出一个具体的估计值,不同的样本算出的估计值也是不同的。 最大似然估计量理论上也只是 依概率 收敛于参数真值的, 因此通常我们使用某个具体的样本算出的估计值和真实值还是不一样的, 估计值和真实值之间到底相差多少, 点估计并没有给出。 本节我们讨论统计学中另一种参数估计方法:区间估计(interval estimate), 也叫 置信区间(confidence interval), 相比于点估计,它能给出有关估计值的更多信息。
样本的点估计值并不是完全等于总体参数真实值的,虽然很接近,但还是存在一定误差的。 在统计学,我们不能用”可能”、”大概”、”也许吧”这样的字眼去描述这个误差, 而是需要给出去一个量化的描述方法, 就像本章开篇引言说的那样。
统计推断除了结论之外,还需要说明结论的不确定程度。–《统计学的世界》
我们已经知道,样本的均值统计量 \(\bar{X}\) 可以作为总体均值参数 \(\mu\) 的点估计量, 而统计量 \(\bar{X}\) 是一个随机量,即不同的样本会得到不同的值,其渐近服从正态分布。
其中 \(\mu\) 和 \(\sigma^2\) 分布是总体的均值参数和方差参数, \(N\) 是样本的容量。

图 3.5.1 均值统计量 \(\bar{X}\) 服从正态分布,样本容量 \(N\) 越大其标准差越小。¶
从 图 3.5.1 可以看出, 均值统计量 \(\bar{X}\) 的值有 \(68.2\%\) 的概率落在区间 \(\mu \pm \sigma/\sqrt{N}\) 范围内,我们知道 \(\mu\) 是总体的真实均值参数,也就是说样本估计值 \(\bar{X}\) 有68.2%的概率和总体真实值 \(\mu\) 之间的误差在一个标准差的范围 \(\pm \sigma/\sqrt{N}\) 内。
但是总体均值参数 \(\mu\) 是未知的,无法得知区间 \(\mu \pm \sigma/\sqrt{N}\) 的具体范围, 这时可以反转一下。 既然 \(\bar{X}\) 有 \(68.2\%\) 的概率落在区间 \(\mu \pm \sigma/\sqrt{N}\) ,反过来就是,\(\mu\) 有 \(68.2\%\) 的概率在区间 \(\hat{\mu} \pm \sigma/\sqrt{N}\) 内, 如 图 3.5.2 所示, \(\hat{\mu}\) 是总体均值 \(\mu\) 的一个具体估计值 (均值统计量 \(\bar{X}\) 的一个具体值), \(\hat{\mu}\) 落在区间 \([\mu-\sigma/\sqrt{N},\mu+\sigma/\sqrt{N}]\) 也可以看成是 \(\mu\) 在区间 \([\hat{\mu}-\sigma/\sqrt{N},\hat{\mu}+\sigma/\sqrt{N}]\) 。
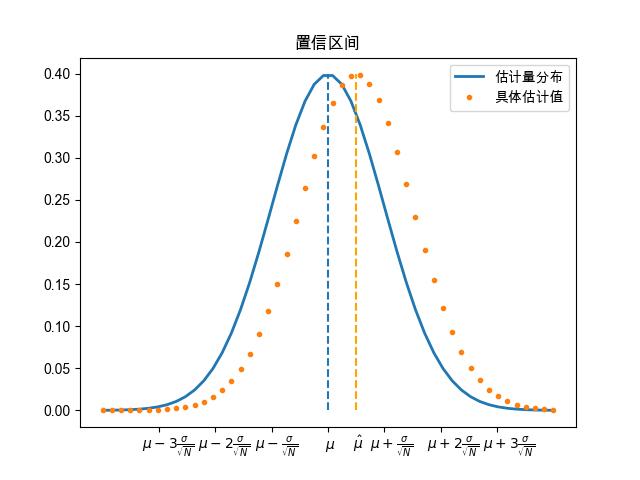
图 3.5.2 估计值 \(\hat{\mu}\) 与总体期望 \(\mu\) 位置是相对的,黄色曲线是蓝色曲线的一个平移。¶
上面的例子中,我们给出的置信区间是上下一个标准差的范围,置信区间的范围可以根据实际情况调整。 我们用 \(\delta\) 表示区间的距离中心点的距离, 则这个区间可以表示成 \([\hat{\mu}-\delta,\hat{\mu}+\delta]\), 这个区间的概率记为 \(1-\alpha\), 则可以记为
区间 \([\text{估计值} \pm \text{误差范围}]\) 称为 置信区间(confidence interval), \(1-\alpha\) 称为 置信度(confidence level),也叫置信系数(confidence coefficient)。 而 \(\alpha(0<\alpha<1)\) 则被称为 显著(性)水平(level of significance), \(\alpha\) 的值通常是事先就确定好的,显然 \(\alpha\) 越大, 置信区间的范围就越小,一般会选择 \(0.01,0.05\) 这样的值。 置信区间的端点被称为 置信限(confidence limits)或者临界值(critical values), \(\hat{\mu} - \delta\) 称为置信下限(lower confidence limit), 而 \(\hat{\mu} + \delta\) 称为置信上限(upper confidence limit)。
在 \(\alpha\) 确定的条件下,置信区间的范围和 \(\delta\) 相关, 而 \(\delta\) 和估计量的标准误差相关,标准误越大,置信区间越宽。 换句话说,估计量的标准误越大,对未知参数的真值进行估计的不确定性越大。 因此,估计量的标准误常被喻为估计量的 精度, 即用估计量去测定真实的总体值有多精确。
相比于原本的似然估计,置信区间给出了一个参数估计区间,因此也称作 区间估计(interval estimate), 顾名思义,区间估计给出的是一个可能包含参数真值的区间。 与之相对的,点估计给出是一个具体的估计(点)值, 相比单纯的点估计,区间估计提供了更加丰富的信息。
置信区间利用了参数估计量的抽样分布,当估计量是无偏估计量时,估计量的期望就是总体参数的真实值, 注意置信区间是根据参数估计量给出的,因此这个区间是随机(量)的, 而参数的真值是一个固定的数值,不是随机值。 因此置信区间解读成:随机(置信)区间包含参数真值的概率是 \(1-\alpha\)。 不能说成: 参数真值落在这个区间的概率是 \(1-\alpha\) 。
概率分布的常见参数有均值参数 \(\mu\) 和方差参数 \(\sigma\) ,这两个参数会一直贯穿本书的全部内容, 为了让大家更深刻的理解,这里我们分别给出两个参数的区间估计的过程。 比较特殊的一点是,均值参数估计量 \(\hat{\mu}=\bar{X}\) 的抽样分布有两种情况, 当已知总体方差 \(\sigma\) 或者样本数量足够大时, \(\hat{\mu}\) 的抽样分布可以选择标准正态分布( \(Z\) 统计量) ,反之需要使用学生t分布(\(T\) 统计量), 两种情况我们都简要介绍一下。
3.5.1. 均值参数的 Z 区间估计¶
虽然已知均值参数估计量的抽样分布是(渐近)正态分布 公式(3.5.1), 但是在计算技术普及前,非标准正态分布的概率值不是很方便计算, 所以通常会转成服从标准正态分布的 \(Z\) 统计量。
其中 \(\mu\) 是总体均值参数的真值,\(\sigma\) 是总体方差参数的真值, \(N\) 是观测样本的数量。 根据置信区间的公式( 公式(3.5.2)),需要找到一个概率为 \(1-\alpha\) 的区间。
由于 \(Z\) 是标准正态分布,区间 \([\delta_1,\delta_2]\) 是以 \(0\) 点为中心左右对称的, 可以记为
\(\alpha\) 的值是事前指定的,假设为 \(5\%\) ,则 \(1-\alpha=95\%\), 根据标准正态分布概率密度的划分情况,可以近似认为在两个标准差的范围,而 \(Z\) (标准正态分布)的标准差是 \(1\), 因此有 \(\delta=2\)。
进一步移项可得
\(\hat{\mu}\) 是先一步利用最大似然估计得到的估计值,在这里是已知的。 如果总体的方差参数 \(\sigma\) 是已知的,这里就已经结束了,已经得到了 \(95\%\) 的置信的区间。 然而实际应用中,\(\sigma\) 通常是未知的,此时如果你的样本数量足够多, 就可以使用 \(\sigma\) 的一个无偏估计值替代。
最后,利用 \(Z\) 统计量得到的均值参数的 \(95\%\) 置信区间为
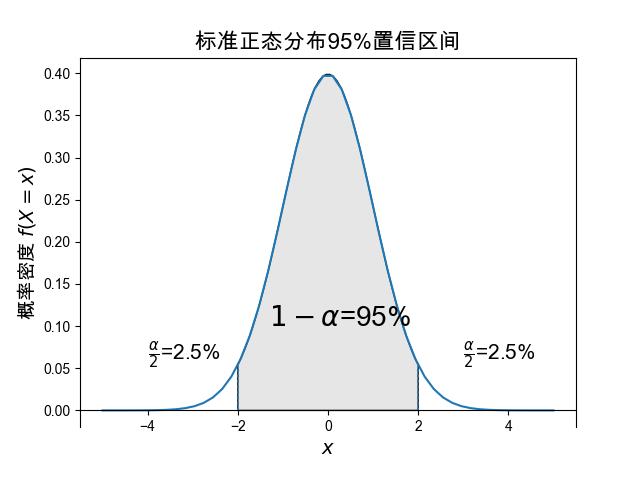
图 3.5.3 标准正态分布95%置信区间 \([-2,2]\)¶
3.5.2. 均值参数的 T 区间估计¶
在 节 3.2.2 讲过, 当总体的方差参数未知或者样本数量小于 \(30\) 的时候, 均值统计量的抽样分布可以用学生t分布替代。 这时在得到对均值参数的置信区间时就要使用学生t分布代替标准正态分布, 实现起来比较简单,是需要把 \(Z\) 统计量换成 \(T\) 统计量。
对于t分布,它的概率区间就不是用标准差来分割了,需要查询t分布临界表或者用计算机去计算得到, t分布的概率是和自由度(\(N-1\))相关的, 假设 \(N=30\),通过查表可得自由度为 \(29\) 的t分布 \(95\%\) 的区间为边界 \(\delta=2.045\), 这比标准正态分布(\(Z\))的 \(2\) 稍微大了一点。 最后,利用 \(T\) 统计量得到的均值参数的 \(95\%\) 置信区间为
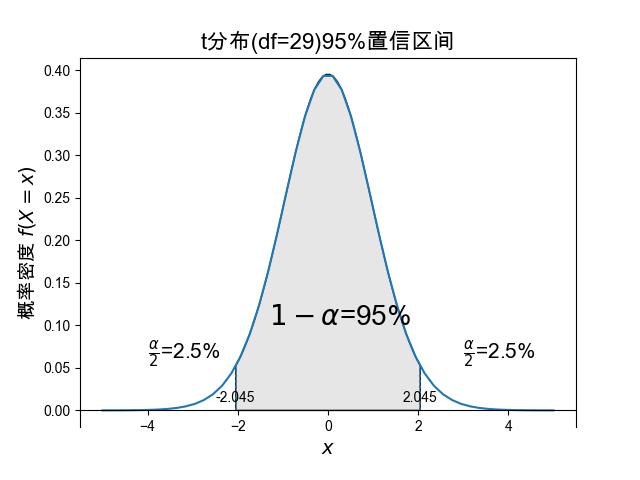
图 3.5.4 自由度为29的t分布的95%置信区间 \([-2.045,2.045]\),相比标准正态分布的95%区间 \([-2,2]\) 稍微大了一些¶
3.5.3. 方差参数的区间估计¶
我们已经知道方差参数的无偏估计量 \(\hat{\sigma}^2\) 是和卡方分布相关的,如下统计量服从自由度为 \(N-1\) 的卡方分布。
获取方差估计量置信区间的过程和上面的均值参数的基本是一样的, 唯一注意的地方是,卡方分布概率密度函数不再是对称的,上界和下界不再对称。 \(1-\alpha\) 的概率区间,相当于是在左右两边各扣除 \(\alpha/2\) 的概率区间, 也就是在分布的左边去掉 \(\alpha/2\) 的概率区间,在分布的右边也去掉 \(\alpha/2\) 的概率区间
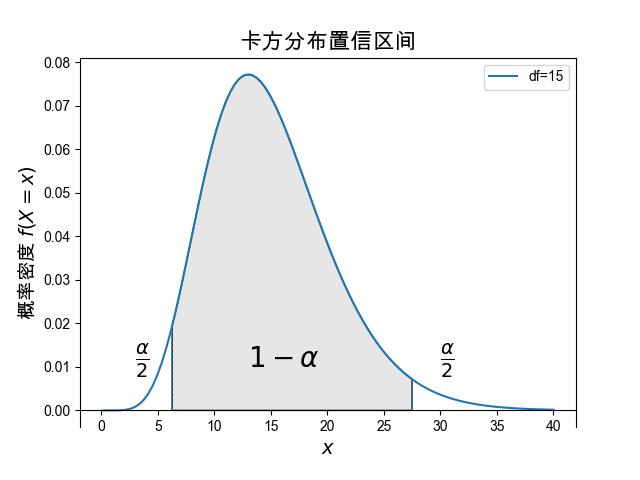
图 3.5.5 卡方分布置信区间,两侧各有 \(\alpha/2\) 的区域被剔除。¶
然后通过查询卡方分布临界表得到分别得到左边界 \(\delta_1\)
和有边界 \(\delta_2\) 的值,也可以利用 python
中 scipy 数学工具包计算得到。
import scipy.stats as st
# 显著水平为5%
alpha = 0.05
# 自有度为 15
df = 15
# 左侧边界
delta_1 = st.chi2.ppf(alpha/2,15)
# 右侧边界
delta_2 = st.chi2.ppf(1-alpha/2,15)
最后调整下 公式(3.5.14) 得到方差参数的置信区间。
3.6. 简单假设检验¶
统计推断是利用样本数据来对总体得出结论。 点估计是使用样本统计量来估计总体参数,但点估计量并不是准确无误的。 置信区间,又叫区间估计,给出了点估计量的不确定性程度。本节介绍统计推断中另一种推断的方法,假设检验(hypothesis testing)。 假设检验(hypothesis testing),或者显著性检验(significance testing)是用来处理有关总体参数或者总体分布的断言。 不同于点估计和区间估计,假设检验不是用来估计总体参数的,而是用来判断对于总体(参数)的某个假设是否成立。
在日常生活中,经常会遇到这样一种情况,我们已经对总体有一个了猜测或者断言,需要去验证这个猜测是不是”正确”的, 或者说这个猜测有多大可能性是正确的。然而总体的真实情况我们是无法得知的,这时就只能通过样本去验证这个猜测, 这就是假设检验做的事情。
举个例子说明下,假设有一个学者发表了一篇关于国人身高的论文,论文中声称国人的平均身高为165cm。 你对这个值有些怀疑,你想验证下这个值是否可信。 然而你又不可能统计出全国所有人民的身高去验证专家的结论是否正确。 通常的做法是,自己随机选择一些身高数据作为样本,然后算出样本的平均值,假设你算出来是160cm, 和学者公布的165cm有些差异。然而这个差异能说明专家声明的165cm是错误的么? 我们知道样本的均值统计量是一个随机量,不同的采样会得到不同的统计值。 那么,这5cm的差异是由于样本的随机性导致的,还是专家的声明是错误的呢? 这可以通过假设检验给出结论。
假设检验(hypothesis testing),又叫显著性检验(significance testing), 检验的过程一般可以抽象成四个步骤。
步骤1. 陈述假设
通常我们把对总体的假设称为零假设(null hypothesis),通常用符号 \(H_0\) 表示, 读作”H零”。\(H_0\) 是对总体的一个假设或者说断言,它是一个虚拟的假设。 比如在我们的例子中,零假设就是:假设专家的声明是正确的,即国人身高的总体均值是165cm。 这是我们做出的一个虚拟假设, 用符号表示记作:
和零假设相反的结论称为备择假设(alternative hypothesis),也可以叫做对立假设, 通常用符号 \(H_a\) 表示。如果零假设 \(H_0\) 不成立, 就意味着备择假设 \(H_a\) 是成立的,通常二者是对立的。 在我们的例子中,备择假设为:
假设检验的过程,就是先假设 \(H_0\) 是正确的,然后在这个前提下寻找 否定 \(H_0\) 的证据, 如果找到”证据”,并且这个证据足够强烈,就拒绝(reject) \(H_0\) ,接受 \(H_a\) ; 如果没有足够的”证据”,就接受(accept) \(H_0\) 。
经过前面的熏陶,我们已经了解到,在统计学中没有什么是绝对的,一切都是通过概率来描述。 这意味用来否定 \(H_0\) 的”证据”也不是绝对的,亦然是”概率”的, 所以用的是接受(accept)、拒绝(reject)这样的词,而不是其他准确判定的词。 因为我们找到的证据并不是百分百的证明 \(H_0\) 是错误的, 只能是从概率上认为 \(H_0\) 成立的可能性”比较小”, 所及拒绝了 \(H_0\) 选择了 \(H_a\) , 假设检验只是一种从概率上选择最有可能的结果,而不是像数学上的证明一样给出绝对的对错。
步骤2. 设定决策标准
假设检验是要找到否定 \(H_0\) 的”证据”, 通常这种”证据”就是在 \(H_0\) 成立的条件下发生了一件”不可能”发生的事件, 所谓的”不可能事件”,就是一件概率很小的事件。 那么这个”不可能”的程度是多少,”概率很小”又有多小?这就需要给出一个标准。 这个标准称为显著水平(level of significance)。
显著水平 \(\alpha\) 通常会设置成5%、2%、1%等值,其含义是只要一个事件发生的概率小于等于 \(\alpha\) 就认为这是一件极端的小概率事件。 在假设检验中,如果在 \(H_0\) 成立的条件下,发生了一件概率小于等于 \(\alpha\) 的事件,认为 \(H_0\) 很可能是错误的,此时会拒绝 \(H_0\)。
步骤3. 计算检验统计量
有了检验标准后,就需要计算出一个值和这个标准比较, 计算这个值的统计量就称为检验统计量,检验统计量有很多种, 一般会根据实际的问题场景选择合适的检验统计量, 然后计算出这个检验统计量的值以及理论上得到这个值的可能性(概率), 这个概率值称为P值(P-value),最后把这个P值和检验标准值 \(\alpha\) 进行比较,并根据比较结果给出结论。
样本均值统计量 \(\bar{X}\) 的抽样分布是正态分布 \(\mathcal{N}(\mu,\sigma^2/N)\) , 通过样本统计量的抽样分布就能计算出样本统计值的发生概率。 在我们的例子中,在 \(H_0\) 成立的前提下,身高总体分布的均值(期望)就是 \(\mu=165\) , 总体的方差未知,暂时用符号 \(\sigma^2\) 表示,则抽样样本的均值统计量 \(\bar{X}\) 的抽样分布是
以上抽样分布的方差 \(Var(\bar{X} )=\sigma^2/N\) 是未知的,其中 \(\sigma^2\) 是总体方差参数, \(N\) 是抽样样本容量,通常样本容量 \(N\) 是已知的,假设抽样样本容量是100。 这时还需要得到总体方差参数 \(\sigma^2\) 才可以,根据点估计的知识,可以用样本方差近似估计总体方差
这里我们假设算出来的总体方差估计值是 \(\hat{\sigma}^2=36.0\), 则样本均值统计量的抽样分布的方差为 \(\hat{\sigma}^2/N=36.0/100=0.36\) ,在 \(H_0\) 成立的条件下,样本均值统计量 \(\bar{X}\) 的抽样分布就为
理论上样本统计量 \(\bar{X}\) 的期望是 \(165\),方差是 \(0.36\)。 然后我们发现,从抽样样本计算得到样本均值为 \(\bar{X}=160\)。 理论上样本结果越接近 \(165\),专家( \(H_0\) )是正确的可能性就越大; 样本均值结果偏离 \(165\) 越远,专家( \(H_0\) )是错误的可能性就越大。
那么样本统计值偏离期望值多远才叫小概率事件呢?总要有个判断标准。 这个标准就是我们在上个步骤中制定的显著水平 \(\alpha\) 。 图 3.6.1 是均值统计量 \(\bar{X}\) 的抽样分布(正态分布)的概率分布曲线。 我们把曲线下方的面积分成两个区域,紧邻期望值两侧的中间区域称为 置信区间, 其面积是 \(1-\alpha\) ,\(1-\alpha\) 是这个区域的面积,也是 \(\bar{X}\) 落在这个区间的概率值,称为 置信水平。在假设检验中这个区域也叫作 接受域,表示我们接受零假设 \(H_0\) 的区域,样本统计值落在接受域的概率是 \(1-\alpha\)。 接受域两侧的阴影区域称为 拒绝域,表示拒绝零假设 \(H_0\) 的区域,其面积总和是 \(\alpha\) , 样本统计值落在这个区间的概率是 \(\alpha\) 。 显著水平 \(\alpha\) 就是对这个”极端小概率”事件的一个标准, 如果统计量 \(\bar{X}\) 的值落在这个区间,我们就认为发生了小概率事件,此时选择拒绝零假设 \(H_0\) 。

图 3.6.1 标准正态分布的区域划分。阴影部分是拒绝域,左右两部分的概率和为 \(\alpha\)。 中间区域是接受域,它的概率是 \(1-\alpha\)。¶
下一步就是要算样本统计值 \(160\) 落在了抽样分布 \(\mathcal{N}(165,0.36)\) 的哪个区域,是落在了接受域还是拒绝域,落在不同的区域会导致我们对 \(H_0\) 做出不一样的选择。 然而在计算机普及之前,要计算出 \(160\) 在正态分布 \(\mathcal{N}(165,0.36)\) 哪个区域不是一件简单的事情, 因此通常并不直接使用均值统计量进行检验(验证)而是使用 Z 统计量, Z 统计量就是均值统计量转化成标准正态分布。
有关 Z 统计量的推导我们在 节 3.2.1 和 节 3.3.4 都有讲到过,可以回顾一下相关内容。 Z 统计量其实就是把服从非标准正态分布的样本均值统计量转换为一个服从标准正态的分布的统计量, 标准正态的分布方便进行检验计算,可以通过查表的方式得出 P 值。 Z 统计量也可以用来衡量样本均值结果值距离期望值有多少个标准差的距离,有时也叫作标准分。
现在我们把样本均值转成成 \(Z\) 的值, 通过计算可得 \(Z=\frac{163-165}{\sqrt{0.36}}=-2/0.6=-3.34\) ,意味着我们的检验统计量的样本值偏离其抽样分布理论期望值 \(3.34\) 个标准差(\(Z\) 的期望值为 \(0\),标准差为 \(1\))远, 负号代表是负偏离,小于期望值。如果是正数,就是大于期望值,是正偏离。
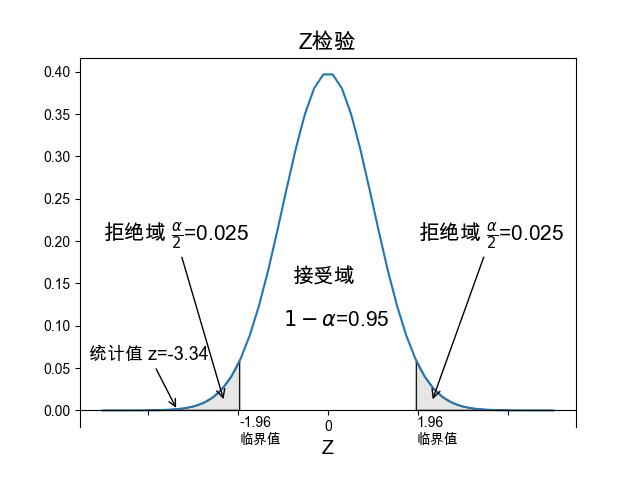
图 3.6.2 当 \(\alpha=0.05\) 时,左右边界分别是 \(-1.96\) 和 \(1.96\), 计算出的 \(z=-3.34\) 正好落在了左侧拒绝域内。¶
步骤4. 做出决策
样本均值 \(\bar{X}\) 结果值163偏离理论期望值165的原因可能有两种, 第一个可能的原因是,正常的随机结果,因为统计量 \(\bar{X}\) 本就是一个随机量,不同样本会得到不同值, 出现不一致是正常的随机现象。 第二个可能原因就是,\(H_0\) 是错误的,\(H_1\) 才是对的, 总体期望不是165,也会导致样本结果偏离理论期望值。 那么如何判断是哪个原因导致现在这个结果呢? 很遗憾,并没有准确的判断方法。我们只能根据概率”接受”其中的一个,这也是假设检验的本质。
理论上,样本结果值偏离理论期望值越远,第二个原因的可能性越大。 换句话说,检验统计量Z的值越大,\(H_0\) 错误的可能性越大。 我们知道统计量 \(\bar{X}\) 是服从正态分布的, 在一个正态分布中,越偏离中心位置的值概率越小, 得到一个远离中心的值是一个概率很小很极端的事件。 因此如果我们通过样本计算得到值在正态分布上是一个很小概率的事件, 就意味发生了一件很极端(概率很小)的事件, 而我们认为通常不会这么”巧合”。 如果在 \(H_0\) 是正确的前提下, 发生了一件极端的事件,我们更倾向于认为 \(H_0\) 是错误的。 本例中计算的到 \(Z=-3.34\), 那么要得到这样一个样本结果值 \(|Z| \ge 3.34\) 的概率是多少呢?
在正态分布中,采样值落到区间 \([\mu, \mu \pm \sigma)\) 的概率大约是68.27%, 落到2个标准差区间 \([\mu, \mu \pm 2\sigma)\) 的概率大约是95.46%, 落到3个标准差区间 \([\mu, \mu \pm 3\sigma)\) 的概率大约是99.73%, 参考 图 1.8.6 。
我们的例子中计算得到 \(Z=-3.34\), 通过查正态分布表可以得到 \(P(|Z| \ge 3.34)=0.08\%\) ,其含义是,正态分布得到一个偏离期望值 至少 3.34的标准差距离的值的概率是 \(0.08\%\)。 这个概率值在假设检验中称作P值(P-value)。
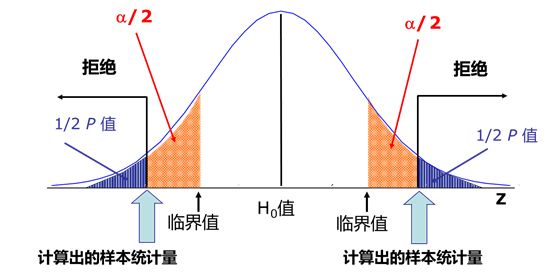
图 3.6.3 双侧检验 P值和 \(\alpha\) 的关系¶
注意我们的备择假设是 \(H_1:\mu \neq 165\),不等于意味着大于或小于, 也就是本例中 \(H_1\) 是包含负偏离和正偏离两个的, 需要计算检验统计量Z落在分布两侧的概率之和,这种正负偏离一起算的检验称为双边检验。 如果把备择假设 \(H_1\) 改成 \(\mu <165\) ,就变成了单边检验,在单边检验中拒绝域只有一侧, 此时只能计算 \(Z \le -3.4\) 的概率。

图 3.6.4 单侧检验 P值和 \(\alpha\) 的关系¶
我们已经计算了P值0.08%,那这个P值是大还是小,算不算极端事件,需要有一个判断标准。 这个标准就是步骤2中设置的显著性水平 \(\alpha\), 如果 \(P \le \alpha\) ,则认为发生了极端事件,此时我们拒绝零假设 \(H_0\), 接受备择假设 \(H_1\); 如果 \(P > \alpha\) ,则认为没有发生极端事件,样本统计值的偏离是正常的随机误差造成的, 此时接受零假设 \(H_0\)。 假设本例中,我们设置显著水平 \(\alpha=1.0\%\) , 显然P值 \(0.08\) 小于显著水平 \(0.1\),因此我们拒绝零假设 \(H_0\) , 我们有理由认为专家是在胡扯。
决策错误
重要
假设检验对总体断言的决策并不是百分百正确的,对于零假设的接受或拒绝的决策是基于概率的, 所以是有可能做出错误的决策的,显著水平 \(\alpha\) 就是做出错误决策的概率的上限。
回顾整个检验过程,从始至终我们都是不知道总体的真实情况的,仅仅根据一份样本统计值做出的决策 ,而决策的判定又是基于概率的,因此假设检验给出的结论也有错误的可能。 零假设的的真实情况和检验结论之间存在四种可能结果。
接受零假设 |
拒绝零假设 |
|
|---|---|---|
零假设为真 |
正确 \(1-\alpha\) |
Type I 错误 \(\alpha\) |
零假设为假 |
Type II 错误 \(\beta\) |
正确 \(1-\beta\) |
表 3.6.1 是用表格的形式给出4种情况, 其中两种结果是正确的,另两种结果是错误的。
零假设为真,并且决策结果是接受,此时决策结果是正确的,这个结果的概率是 \(1-\alpha\)。
零假设为真,然而决策结果是拒绝,此时决策结果是错误的,这个结果的概率是 \(\alpha\)。
零假设为假,然而决策结果是接受,此时决策结果是错误的,这个结果的概率是 \(\beta\),此时称为Type I 错误。
零假设为假,并且决策结果是拒绝,此时决策结果是正确的,这个结果的概率是 \(1-\beta\),此时称为Type II 错误。
Type II 错误
如果检验的决策是接受零假设,那么这个结果有可能是正确的也可能是错误的。 如果零假设实际上是错误的,那么我们就做了一个错误的决策,此时称为 Type II 错误,又叫 \(\beta\) 错误,\(\beta\) 表示做出错误决策的概率, 当然这个 \(\beta\) 的值我们是无法得知的。
假设检验的零假设通常是对事物或者总体已有的一个认知或者结论,我们通过假设检验去论证这个认知是否正确, 如果假设检验的决策是 \(\beta\) 错误,相当于我们的检验过程其实没有贡献什么, 并没有判断出来这个零假设是错误的。更可悲的是,我们自己并不知道发生了 \(\beta\) 错误。
Type I 错误
同样的,如果检验的决策是拒绝零假设,也有可能是错误的决策。 零假设是真实的,但决策结果是拒绝零假设,我们把这类型的错误称为 Type I 错误。 幸运的是,我们能掌控犯 Type I 错误的概率上限, Type I 错误发生的概率上限就是显著水平 \(\alpha\) 。我们通过比较P值和 \(\alpha\) 做出拒绝零假设决策, 因此 \(\alpha\) 就是代表着我们做出 拒绝零假设 决策的概率, 也就是犯 Type I 错误的 概率上限 , 注意 \(\alpha\) 不是 Type I 错误的概率,而是其理论上限, 可以通过减小显著水平 \(\alpha\) 的值,来降低 Type I 错误的概率。 但是,并不能一味的降低 \(\alpha\) 的值, 随着 \(\alpha\) 的降低,我们拒绝零假设的条件就更加严苛,减少了拒绝零假设的可能性, 因此也就减少了检验出错误零假设的能力(power)。
假设检验的关键思想在于一个检验统计量(test statistic)及其在虚拟假设下的抽样分布, 根据观测数据算出检验统计量值决定是否接受 \(H_0\)。 其过程概括起来就是
对总体某个参数的值做出一个虚拟的假设,称为零假设,记作 \(H_0\)。与 \(H_0\) 不同的结果是对立假设,记作 \(H_a\)。
选择一个和这个参数相关的检验统计量,并根据样本和虚拟假设的参数值计算出这个检验统计量的值,然后算出检验统计量值对应的 \(P\) 值。 所谓 \(P\) 值就是,在检验统计量的抽样分布下,得到检验统计量值及其更极端值的概率。
根据 \(P\) 值和显著水平 \(\alpha\) 做出接受还是拒绝零假设的决策。
习惯上会根据检验统计量(抽样分布)对检验过程进行命名, 比如利用 \(Z\) 统计量进行假设检验就称为 \(Z`检验, 利用 :math:`T\) 统计量进行假设检验就称为 \(T\) 检验, 利用 \(\chi^2\) 统计量进行检验就称为 \(\chi^2\) 检验, 下面我们分别对这些检验进行简单的介绍。
3.6.1. Z检验¶
和均值参数相关的统计量有两个 \(Z\) 统计量和 \(T\) 统计量, 当总体方差已知或者抽样样本足够多时,使用 \(Z\) 统计量即可, 当总体方差未知并且抽样样本比较少时,建议使用 \(T\) 统计量。 本节我们先介绍用 \(Z\) 统计量对均值参数进行检验, 下一节讨论如何用 \(T\) 统计量对均值参数进行检验。
假设我们要对某个总体的分布的均值参数 \(\mu\) 进行检验, 总体的方差参数 \(\sigma^1\) 认为是已知的。 我们对均值参数 \(\mu\) 做出一个虚拟的假设, 假设它的真实值为 \(\mu^*\) ,零假设就是
与零假设结果相反的对立假设为
然后我们得到一个容量为 \(N\) 的抽样样本(观测样本), 利用这个样本可以得到 \(\mu\) 的一个估计值,记作 \(\hat{\mu}\) ,估计量 \(\hat{\mu}\) 的标准误差为 \(\sigma/\sqrt{N}\), 然后就可以计算出 \(Z\) 统计量的一个值,记作 \(z\) 。
最后看 \(z\) 落在了哪个区域,如果落在接受域,则接受零假设,即认为零假设是正确的。 反之,如果落在拒绝域,就拒绝零假设。 判断 \(z\) 落在哪个区域有两种方法。
第一种方法,在给定显著水平 \(\alpha\) 的值后,计算出临界值 \(\delta_1,\delta_2\) ,这和上一节置信区间的方法是一样的,可以算出接受域(置信)区间 \([\delta_1,\delta_2]\) ,然后判断 \(z\) 值是否在区间 \([\delta_1,\delta_2]\) 内即可得出结论。 从这里可以看出,建设检验和置信区间本质上(区间估计)是一样的。
第二种方法,先计算出 \(P\) 值, 即 \(P(|Z|>z)\), 如果 \(P \leq \alpha\) 则说明 \(z\) 值落在了拒绝域, 反之,如果 \(P>\alpha\) 则说明 \(z\) 值落在了接受域。
公式中 \(\Phi\) 是标准正态的分布的累积分布函数,由于标注正态分布是对称的, 因此有 \(P(Z \geq z)=P(Z \leq -z)\)

图 3.6.5 双侧Z检验¶
3.6.2. T检验¶
当总体方差参数 \(\sigma\) 未知并且抽样样本数量比较少时, 就用 \(T\) 检验替代 \(Z\) 。 \(T\) 检验和 \(Z\) 检验的过程是完全一样的, 甚至二者的统计量值计算公式都是相似的,不一样的地方在于用 \(\hat{\sigma}\) 代替 \(\sigma\)。
不一样的地方仅在于计算 \(P\) 值的时候,要使用学生t分布的累积分布函数。 我们用符号 \(\mathcal{T}_{n}\) 表示自由度为 \(n\) 的学生t分布的累积分布函数,则 \(P\) 值的计算方法为
\(T\) 统计量(公式(3.6.11))与 \(Z\) 统计量(公式(3.6.9))的公式看上去是一样的, 二者之间的差别就在于分母部分,如果其中 \(\sigma\) 是总体分布的真实方差得到的就是 \(Z\) 统计量,服从标准正态分布; 如果用的是方差估计值 \(\hat{\sigma}\) 得到的就是 \(T\) 统计量,服从学生 t 分布。 当然如果样本数量 \(N\) 无穷大,\(T\) 统计量就近似等于 \(Z\) 统计量。
3.6.3. 卡方检验¶
卡方检验常用于对方差参数进行检验, 零假设是对方差参数的一个虚拟假设 ,假设方差参数的值为 \(\sigma^*\) ,然后通过卡方检验决定是否接受这个假设。
设方差参数的零假设和对立假设分别为
然后利用容量为 \(N\) 的样本得到方差参数的一个无偏估计值 \(\hat{\sigma}^2\) ,有了 \(\hat{\sigma}^2\) 和 \(\sigma^*\) 后, 可以计算出卡方统计量的值。
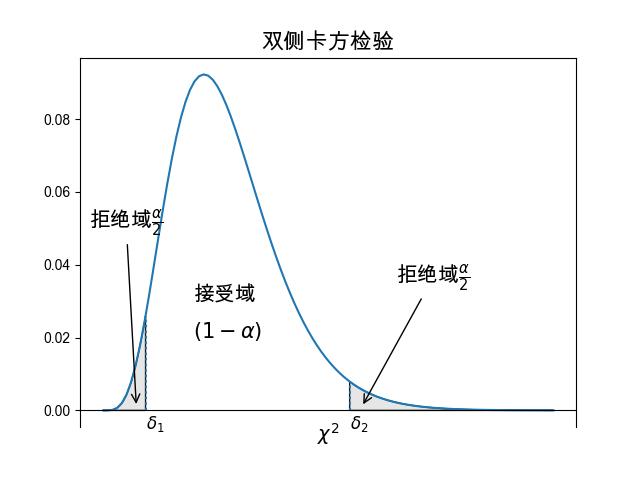
图 3.6.6 双侧 \(\chi^2\) 检验¶
这里要注意 \(\chi^2\) 分布不再是对称结构, 如果是双边检验,无法直接计算出 \(P\) 值, 此时可以先算出接受(置信)域区间 \([\delta_1,\delta_2]\), 如 图 3.6.6 所示, 然后根据 \(\chi^2\) 值是否落在这个区间做出决策。
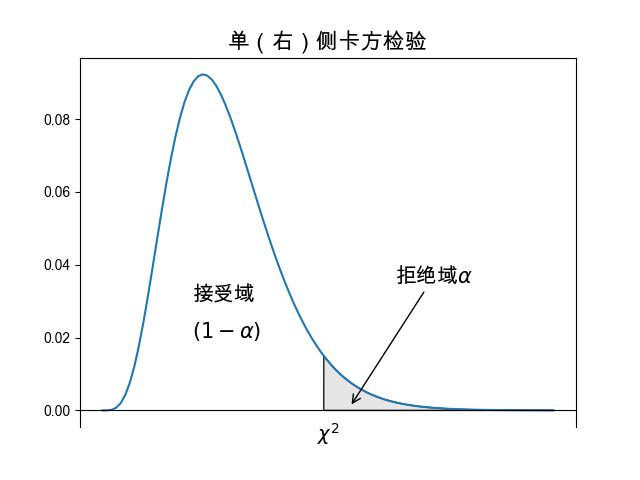
图 3.6.7 单侧 \(\chi^2\) 检验¶
事实上,由于卡方分布是左偏的,整个图形期望值距离左侧很近,而右侧是一条长尾, 所以多数情况下,卡方检验使用的是单(右)侧检验, 如 图 3.6.7 所示。 此时可以计算出 \(P\) 值, 比较 \(P\) 值和显著水平 \(\alpha\) 大小做出决策。