13. 二项式模型¶
在机器学习领域,应用最广的两个模型,一个是线性回归模型
另一个就是逻辑回归模型。
线性回归模型就是采用标准连接函数的高斯模型,
高斯模型是处理连续值数据的基本模型。
而逻辑回归模型是处理二分类数据的基本模型,
逻辑回归模型就是标准连接函数的二项式回归模型。
二项式回归模型对应的是指数族中的二项式分布,
二项式分布是统计学中最常见的概率分布之一,应用十分广泛。
本章我们讨论 GLM 框架下的二项式回归模型。
13.1. 伯努利分布¶
如果一个随机变量只有两种可能状态,就可以认为这个随机变量服从伯努利分布(Bernoulli distribution)。 比如,在广告场景中,用户点击广告的行为可以分成点击和不点击两个状态; 投掷一枚硬币,只能是正面向上或者反面向上(排除硬币站立的情况) 。服从伯努利分布的随机变量通常称为伯努利变量, 伯努利变量只有两个不同的状态,因此它是离散随机变量,伯努利分布属于离散概率分布。
通常会用数字 \(0\) 和 \(1\) 分别表示伯努利变量的两种状态, 假设状态为 \(1\) 的概率是 \(\pi\) ,那么状态为 \(0\) 的概率就是 \(1-\pi\) 。伯努利概率分布的概率分布函数通常可以写成
\(Y=1\) 的概率和 \(Y=0\) 的概率分别为
伯努利分布的期望和方差分别是
可以看出 \(\pi\) 其实就是分布的期望参数 \(\mu\) ,并且伯努利分布的方差是期望的一个二次函数。 伯努利分布仅有一个期望参数, 因此它是一个单参数的概率分布 。
伯努利分布是离散变量的概率分布, 离散分布的概率分布函数称为 概率质量函数 ,概率质量函数的值直接就是概率值。 这一点和连续值分布是不同的,连续值分布的概率分布函数叫做 概率密度函数 ,概率密度函数的值并不是概率值,需要积分才能得到概率值。
13.2. 逻辑回归模型¶
13.2.1. 模型定义¶
假设响应变量 \(Y\) 是一个伯努利变量, 它的概率分布函数如 公式(13.1.1) 所示, 现在把它转化成指数族的形式
由于参数 \(\pi\) 就是分布的期望 \(\mu\) ,因此我们直接用符号 \(\mu\) 替换 \(\pi\) 。
和指数族的自然形式对比下,可以直接给出各项的内容。
它的期望可以通过累积函数的一阶导数求得
方差函数通过累积函数的二阶导数得到
分散函数和方差函数的乘积就是分布的方差
可以看到伯努利分布的方差不是常量,而是关于期望参数 \(\mu\) 的二次函数, 显然伯努利分布的方差会受到期望 \(\mu\) 的影响。
根据标准连接函数的定义,标准连接函数是使得线性预测器 \(\eta\) 等于自然参数 \(\theta\) 的连接函数,所以对于伯努利分布,其标准连接函数就是
在统计学中,这个函数称为 logit (/ˈloʊdʒɪt/ LOH-jit) 函数,
逻辑回归模型的标准连接函数就是 logit 函数,它的一阶导数为
响应函数是连接函数的反函数,
logit 函数的反函数为
logit 函数的反函数就是我们熟知 logistic 函数,
logistic 函数中文叫做 逻辑函数
,它是标准连接的伯努利回归模型的响应函数
,因此一般把伯努利回归模型叫做 逻辑回归模型(logistic regression model)
。
备注
很多人把 logistic 函数称为 sigmoid,这是不准确的。
sigmoid 定义是:拥有S形状的一类函数。sigmoid 是一类函数的统称,并不是特指某一个函数,
logistic 函数是 sigmoid 中的一例,其它的还有 Arctangent 函数、
Hyperbolic tangent 函数
、Gudermannian 函数等等。
最后整理下逻辑回归模型的关键组件
13.2.2. 参数估计¶
大部分有关逻辑回归模型的资料中,都是采用完全最大似然法估计模型的参数,
比如梯度下降法、牛顿法等等。
然而逻辑回归模型是可以纳入到 GLM 框架中的,
因此逻辑回归模型也是可以用 IRLS 算法进行的参数估计的。
逻辑模型的对数似然函数为
IRLS 算法中权重矩阵 \(W\) 和工作响应矩阵 \(Z\) 的计算公式分别为:
偏差统计量为:
13.2.3. odds 与 logit¶
在 GLM 中连接函数的作用是把线性预测器 \(\eta\) 和响应变量的期望值 \(\mu\)
连接在一起,本质上就是把 \(\eta\) 的空间和 \(\mu\) 的空间进行映射,
并且这种映射关系必须是 双射 ,也就是对于任意一个 \(\eta\)
都可以得到一个唯一的 \(\mu\) 与之对应,反过来也成立,对于任意一个 \(\mu\)
都可以得到一个唯一的 \(\eta\) 与之对应,
这就要求连接函数必须是单调可逆的。
在很多有关 logistic 回归模型的资料中都会提到一个概念,odds ,
为了令读者对二项式回归模型理解的更透传,
这里我们介绍下 odds 与标准连接函数 logit 的关系。
学过基础数学技能的人都知道,概率(probability)是用来描述事件发生的可能性的。 概率一般是通过频次来计算的,比如投掷一枚骰子 \(n\) 次,其中点数 \(1\) 的次数是 \(a\) ,那么点数 \(1\) 概率为
点数不是 \(1\) 的概率为
用概率来描述事件发生可能性是符合人的直觉的,
因此在日常生活中概率的应用是广泛的。
然而在统计学中,除了概率以外,还可以用 几率(odds)
来描述事件发生的可能性。在英语里,odds 的意思就是指几率、可能性。
odds 指的是 事件发生的概率 与 不发生的概率 之比。
在上面的例子中,点数为 \(1\) 的 odds
为
可以看到事件总次数 \(n\) 是可以被抵消掉的,
因此 odds 也可以看做是频次之比。
由于 odds 是概率或者频次的比值,显然 odds 的取值范围是
\([0,\infty)\)
,odds 的值越大,事件发生的可能性就越大。
概率的值域范围是 \([0,1]\)
,而 odds 的值域范围是 \([0,\infty)\)
,从概率到 odds 的转变,实现了值域的改变。
如果对 odds 取自然对数,就得到了 logit
odds 的自然对数就称为 logit
,logit 是 log-it 的简写。
odds 取自然对数后,输出值的范围就变成了 \((-\infty,\infty)\)
,正好和线性预测器 \(\eta\) 的值域范围变得一致了。
从概率到 logit 值域范围的演变过程为
逻辑回归模型的期望值 \(\mu\) 就表示一个概率值,
其取值范围是 \([0,1]\)
。线性预测器 \(\eta\)
的取值范围是 \((-\infty,\infty)\)
。 logit 作为逻辑(二项式)回归模型的标准连接函数,
其作用就是实现 \(\mu\) 到 \(\eta\) 的映射。
13.3. 二项式分布¶
在英语语境中,会把随机变量的单次采样称为一次实验,
连续多次独立实验的结果形成的序列,称为一次 trial 。
如果把伯努利变量进行多次独立取样,
就得到一个伯努利状态序列,
如果把这个序列中状态为 \(1\) 的次数看做一个随机变量,
这个变量就是一个二项式(binomial)变量,
二项式变量的概率分布称为二项式分布(binomial distribution)。
二项式分布表示进行 \(n\) 次伯努利实验,状态 \(1\) 的次数的概率分布。
假设响应变量 \(Y\) 服从二项式分布,
则概率分布函数为
其中符号 \(\pi\) 表示单次伯努利实验状态为 \(1\) 的概率,也就是伯努利分布的期望参数。 符号 \(n\) 是进行的实验次数,通常是已知的常量。 可以看出二项式分布的概率分布函数就是在伯努利概率分布函数的基础上加了组合数 \(\binom{n}{y}\) ,之所以是组合数,而不是排列数,是因为二项式随机变量 \(Y\) 表示的次数,与顺序无关,因此是组合数。
二项式分布的期望和方差分别是
通常实验次数 \(n\) 是已知的常量,并不是未知参数, 二项式分布的未知参数只有 \(\pi\) ,这和伯努利分布是同一个参数。 事实上,伯努利分布是二项式分布的一个特例, 二项式分布中,当 \(n=1\) 时,就是退化成了伯努利分布。 因此,有些资料中,把伯努利分布也称作二项式分布,这是合理的。
13.4. 二项式回归模型¶
13.4.1. 模型定义¶
假设响应变量 \(Y\) 服从二项式分布,其概率分布函数为
其中 \(\pi\) 是单次实验成功的概率,\(n\) 是实验的总次数, \(y\) 是成功的次数,这个分布函数中 \(\pi\) 是唯一的参数。 转化成自然指数族的形式为
和指数族的自然形式对比下,可以直接给出各项的内容。
累积函数的一阶导数和二阶导数分别为
通过累积函数的导数可以分别得到分布的期望和方差,
同样,二项式分布的方差是关于期望的一个函数,方差会受到期望的影响。
二项式分布的自然参数和伯努利分布的自然参数是完全一样,
因此二项式模型的标准连接函数也是 logit
函数。
连接函数的导数为
二项式模型的响应函数同样也是 logistic 函数。
对比下伯努利回归模型与二项式回归模型, 可以看出,无论是连接函数还是响应函数,仅仅只是差了一个常量 \(n\) 而已,而 \(n\) 是一个已知的常量,并且当 \(n=1\) 时,二者就完全一样了。 连接函数都是映射的线性预测器 \(\eta\) 与 \(\pi\) 的关系,这和 \(n\) 无关。 因此可以认为 伯努利模型和二项式模型是同一个模型,二项式回归模型也是逻辑回归模型 。
虽然严格来说二项式分布的期望是 \(\mu=n\pi\) ,但是由于 \(n\) 是已知常量,仅仅起到一个倍数的作用, 所以在强调 期望参数 时,可以只考虑 \(\pi\) , 而忽略 \(n\) 。这一点请铭记,否则在看某些资料时会迷惑!
最后,我们汇总下二项式回归(逻辑回归)模型的一些关键组件。
13.4.2. 参数估计¶
二项式回归模型的对数似然函数为
IRLS 算法中 \(W\) 和 \(Z\) 的计算公式分别为
偏差统计量为
我们用符号 \(o_{ik}\) 表示从样本中 观测(observed) 到的 \(k\) 个状态的次数, 比如 \(o_{i0}\) 表示失败的次数 \(n_i-y_i\) ,\(o_{i1}\) 表示成功的次数 \(y_i\) 。用符号 \(e_{ik}\) 表示模型 拟合(fitted) 的结果, 比如 \(e_{i0}\) 表示模型预测的失败的次数 \(n_i-\hat{\mu}_i\) ,\(e_{i1}\) 表示模型预测的成功的次数 \(\hat{\mu}_i\) 。 则偏差统计量可以简写为
二项式模型的偏差统计量是不包含冗余参数的,比如分散参数 \(\phi\) ,所以可以直接用它的渐近分布进行假设检验。
注意对于 \(n_i\) 比较小的数据,这个近似的效果会比较差。
二项式模型的皮尔逊卡方统计量为
二项式模型的卡方统计量 \(\chi^2\) 和偏差统计量 \(D\) 是近似相等,可以用泰勒级数进行证明,这里省略证明。 当 \(n_i\) 比较小时,卡方统计量会比偏差更准确一些, 但是但 \(n_i\) 非常小时,无论偏差统计量还是卡方统计量都不在准确。
13.5. 其它连接函数¶
我们已经很清楚连接函数的作用了, 它的的作用就是把线性预测器 \(\eta\) 和模型的期望参数 \(\mu\) 进行可逆的映射 。二项式模型的期望参数 \(\mu=\pi\) (注意,这里我们忽略 \(n\) ) 是一个概率值,它的合理取值范围是 \([0,1]\) 。因此,能用来做二项式模型响应函数(连接函数的反函数)的函数, 它的输出域就必须是 \([0,1]\) 。 而在统计学中,有一类函数是符合这个特点的,那就是概率分布的 累积分布函数 。 概率分布的累积分布函数,满足单调性,并且输出域是 \([0,1]\) ,因此累积分布函数的反函数是可以作为二项式模型的连接函数的。
假设函数 \(f(s)\) 是一个概率密度(质量)函数,其累积分布函数 \(F(s)\) 就是对 \(f(s)\) 的积分。
其中 \(f(s)\ge0,\int_{-\infty}^{\infty} f(s)ds=1\) ,累计分布函数表示的是随机变量 \(s\) 大于等于 \(t\) 的概率, \(P(s \ge t)\) , 显然,\(F(s)\) 的输出范围是 \([0,1]\) 。
13.5.1. 恒等连接函数¶
首先我们看下均匀分布的累积分布函数, 假设概率分布函数 \(f(s)\) 是均匀分布的概率密度函数, 随机变量 \(s\) 的范围是 \([c_1,c_2]\) ,均匀分布 \(f(s)\) 的概率密度函数为
均匀分布的累积概率分布函数 \(F(x)\) 是
令 \(\beta_1=\frac{-c_1}{c_2-c_1}\) , \(\beta_2=\frac{1}{c_2-c_1}\) ,此时 \(F(x)\) 等价于
\(F(x)\) 就是响应变量的期望 \(\mu\) ,线性部分就是 \(\eta\) , 连接函数 \(g(\mu)\) 就是恒等函数, 恒等连接函数就相当于是均匀分布的累积概率分布函数。
但是恒等连接函数有个限制,就是只有 \(x\) 在区间 \([c_1,c_2]\)
才有意义,此时参数 \(\beta\) 也被约束在某个区间内。
然而,GLM 的通用参数估计算法 IRLS 并不能解决带约束的参数估计问题,
因此恒等连接函数在二项式模型中并不常用。
13.5.2. probit 回归¶
现在我们看下正态分布的累积分布函数。 假设概率分布 \(f(s)\) 是标准正态分布 \(\mathcal{N}(0,1)\) ,其CDF又称为累积正态分布函数(cumulative normal distribution function,CNDF), 累积正态分布函数是对标准正态分布 \(\mathcal{N}(0,1)\) 概率密度函数的积分。 习惯上用符号 \(\phi(x)\) 表示标准正态分布的概率密度函数, 用符号 \(\Phi\) 表示累积正态分布函数,注意不要和指数族的分散参数搞混,在这里不是尺度参数。 累积正态分布函数为
它的反函数通常称为 probit 函数,用符号 \(\Phi^{-1}(x)\) 表示。
采用 probit 函数作为连接函数二项式回归模型称为 probit 回归模型,
probit 和 logit 非常的类似,二者的(反)函数图像都是 \(S\) 型曲线,
并且以点 \((0,0.5)\) 为对称点呈现对称结构,二者只是在曲率上稍微有些差别。

图 13.5.1 logit 和 probit 函数曲线对比。¶
对二值或分组的二项式数据使用 probit 回归模型通常会产生与逻辑回归相似的输出。
但是 logit 模型可以解释为胜率比(odds ratio),而 probit 没有这样的解释。
但是,如果线性关系中涉及正态性(通常在生物学领域中就是如此),
则 probit 可能是合适的模型。
当研究人员对赔率不感兴趣而对预测或分类感兴趣时,也可以使用它。
然后,如果 probit 模型的偏差显着低于相应的 logit 模型的偏差,则首选前者。
当然,比较二项式家族中的任何连接函数时,偏差小的模型永远是最优的选择。
我们可以非常容易的应用 IRLS 算法对 probit 模型进行参数估计,
只需要替换算法中的连接函数 \(g\) 、响应函数 \(r\) ,
以及连接函数的导数 \(g'\) 。
\(probit\) 连接函数相比 \(logit\) 连接函数复杂了很多, 它不如 \(logit\) 更加的流行。 但是,当特征数据存在正态性时,\(probit\) 可能更合适。
13.5.3. log-log 和 clog-log¶
logit 和 probit 的曲线都是以点 \((0,0.5)\) 对称的”S”型曲线,
所以,二分类 logit 和 probit 模型假定响应数据中为 \(0\) 和 \(1\) 的比例是相同的。
然而,当响应数据中 \(0\) 和 \(1\) 的比例相差巨大时,
clog-log 或 log-log 可能会提供更好的模型效果,
因为它们具有非对称性,这些不对称的连接函数有时会更适合特殊的数据情况。
clog-log 和 log-log 是不对称的”S”型,
对于 clog-log 模型,S曲线的上部比 logit 或 probit 更大或更长;
而 log-log 模型恰好相反,S曲线的底部向左拉长或倾斜。
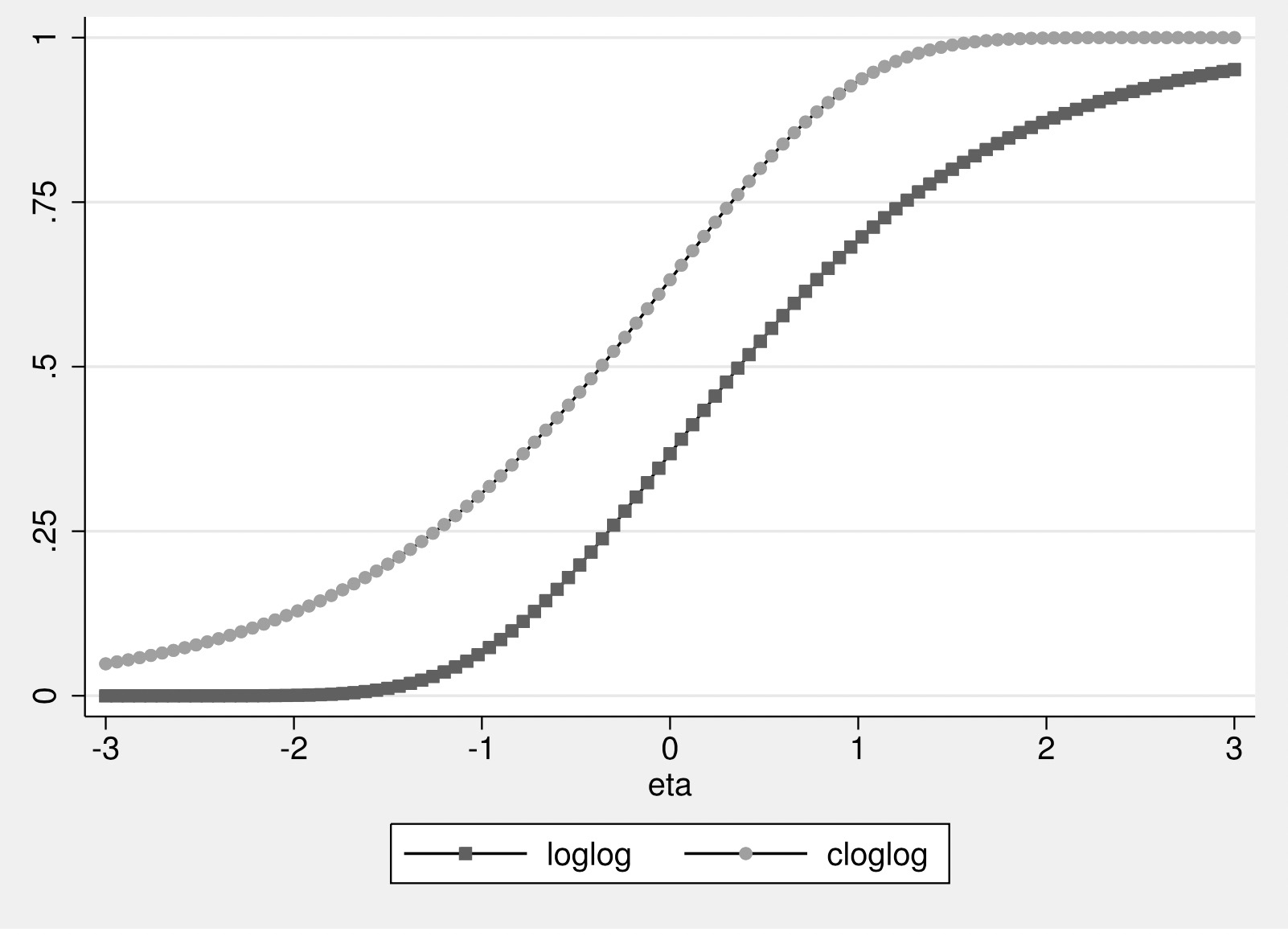
图 13.5.2 clog-log 和 log-log 函数¶
上图展示了 clog-log 和 log-log 连接函数的非对称性,
非对称结构使得我们可以更关注其中的一类。
假设在二分类场景中, \(y\) 表示样本是正类的概率,
\(\bar{y}=1-y\) 表示样本是负类的概率。
如果我们使用对称的连接函数,则可以拟合一个同时适用于两个类别的模型,
两个类别的模型仅仅是系数的正负号不同。
此时,
\(probit(y)\) 和 \(probit(\bar{y})\) 是互补的,
\(logit(y)\) 和 \(logit(\bar{y})\) 是互补的。
但这在非对称的链接模型中,将不再适用,
在非对称连接函数 log-log 和 clog-log 的情况下,
\(loglog(y)\) 不再和 \(loglog(\bar{y})\) 互补,
\(cloglog(y)\) 不再和 \(cloglog(\bar{y})\) 互补,
而是 \(loglog(y)\) 与 \(cloglog(\bar{y})\) 互补。
下面用公式展示出各自的互补关系。
直观的来讲,就是在对称链接的情况下,有 \(r(\eta)+r(-\eta)=1\) ,
而在非对称链接的情况下 \(r(\eta)+r(-\eta) \neq 1\) ,
clog-log 和 log-log 的关系是对称的, \(r_{loglog}(\eta)+r_{cloglog}(-\eta) = 1\)
。
log-log
Clog-log
13.6. 分组数据与比例数据¶
伯努利模型对应着二分类的场景,也就是一条数据可以有0或1两个类别,此时响应变量的值 \(y_i\) 就是类别, 模型预测每条数据所属的类别。 而二项式模型中,一条数据就表示一组实验结果,相比于伯努利数据,每条数据中多了一个表示实验次数的 \(n_i\), 响应变量的值 \(y_i\) 不再是0或1的二分类值,而是表示 \(n_i\) 次实验中成功的次数,其取值范围是 \(0 \le y_i \le n_i\) 。
举个实际的例子说明下,假设有两个赌徒想预测一个篮球运动员的投篮命中率。 一个赌徒的做法是, 收集了这个球员 每次投篮时 的身体状态信息、天气状态、队员状态、对手状态等等信息,以及本次投篮行为的结果, 进球还是没进球。然后训练了一个 伯努利模型(二分类模型) 预测球员 单次投篮进球的概率 。 另一个赌徒的做法是,收集这个球员 每场比赛 的信息,这个球员在每场比赛中投了几次,进了几次,以及其它一些信息。 然后训练了一个 二项式模型 预测球员的 一场比赛中进球率,即在投篮n次的情况下进球几次。
在二项式模型下,一条数据表示一组实验的结果,并且多了一个表示试验次数的 \(n_i\) , \((x_i,n_i,y_i)\) , 此时样本数据称为分组数据(grouped data),一条数据相当于一个组。 然而有时数据中的 \(n_i\) 是缺失的,并且 \(y_i\) 不再是成功次数,而是成功的比例 \(y_i'=y_i/n_i\) ,此时数据样本变成 \((x_i,y_i')\) , 这时称为比例(proportional)数据 。
有些时候数据中可能缺少实验次数、成功次数这样的数据,而仅有一个比例数据,即成功率, 响应变量 \(Y\) 的值是一个 \([0,1]\) 的比例值。 此时,可以使用线性回归模型拟合这个比例值, 但是,线性回归模型的输出值可能会超出 \([0,1]\) 的区间范围。 这时,我们可以先把 \(y\) 值转换一下 。
经过 logit 函数转换后,新的 \(y_{new}\) 值就是实数域范围了,然后再应用线性回归模型。
但是注意 logit 函数不能处理0和1的样本值。